您可以在 E-MapReduce(简称“EMR”)集群详情的告警管理界面,配置不同组件产生对应事件类型时的告警规则,方便您及时感知组件的状态及事件类型的严重等级。本文将为您介绍创建告警规则的方式和组件事件类型的规则列表。
说明
本文档适用于3.2.0 / 2.1.1 及以前版本的集群,若您的集群版本较新,告警相关文档请参阅:告警中心。
进入告警管理
- 登录 EMR 控制台。
- 左侧导航栏点击集群列表 > 具体集群名称,进入集群详情。
- 在上方功能栏中,点击告警管理,进入告警管理界面。
展示告警规则信息。具体说明如下:
内容 | 说明 |
|---|---|
告警规则名称 | 展示告警规则的名称,可用户自定义 |
更新时间 | 展示最近一次编辑告警规则的时间 |
操作用户 | 展示最近一次编辑告警规则的用户名称 |
状态 | 支持开启或关闭告警规则 |
操作 | 支持编辑或删除告警规则 |
创建告警规则
- 点击右上角创建告警规则按钮。
- 在弹窗中,输入规则名称:只允许包含中文、字母、数字、-、_等符号。
- 告警项范围:支持指定告警项的范围,您可以指定集群或具体的节点为告警范围。
- 选择要订阅的事件类型以相应的严重等级,具体事件类型,详见下方:2.1 规则列表。
注意
只有当对应严重等级的事件触发时,才能获取到事件通知。
- 通知方式:
支持选择站内信、邮件、短信、飞书、电话等通知方式,不同的通知方式有对应的信息需要补充:- 飞书:
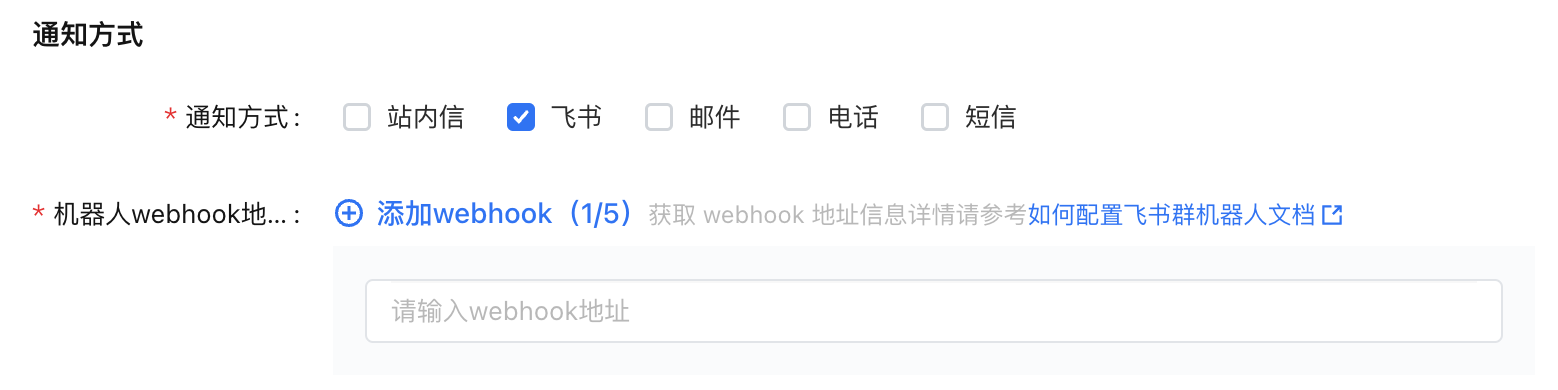
飞书类型的通知方式,需要您提供对应的 webhook 地址,以便发送通知到对应的飞书机器人上。获取 webhook 地址信息详见如何配置飞书群机器人文档。 - 邮件、短信、电话:
- 勾选后,会弹出一个联系人的多选下拉单,这个下拉单对应到含主账号在内的所有用户列表。其中主账号始终置顶。
- 对于选中的用户,在进行通知时,会根据账号管理中配置好的安全邮箱与安全手机,进行对应的消息发送。
- 飞书:
- 配置完毕后,点击确认按钮,即完成告警规则的创建。
规则列表
组件 | 等级 | 事件 | 备注 |
|---|---|---|---|
HDFS | 严重 | NameNode 进程状态 | 如果监听不到或者确认不了 NameNode 进程是否正常,则会触发 CRITICAL 警报。 |
NameNode Blocks 健康状况 | 如果存在 NameNode Blocks 丢失的情况,则会触发 CRITICAL 警报。 | ||
NameNode 容量使用情况 | 如果 NameNode 已使用容量达到总容量的 80%,则会触发 CRITICAL 警报 | ||
NameNode RPC 延迟状况 | 如果 NameNode RPC 延迟大于5000ms,则会触发 CRITICAL 警报 | ||
DataNode 健康状况 | 如果存在不健康的 DataNode,则会触发 CRITICAL 警报。 | ||
DataNode Service RPC 队列延迟(每小时) | 如果 DataNode 端口上的 RPC 队列延迟偏差在一个小时内超过了200ms,则将触发 CRITICAL 警报。 | ||
NameNode Client RPC 队列延迟(每小时) | 如果 NameNode Client 端口上的 RPC 队列延迟的偏差在一个小时内超过200ms,则将触发 CRITICAL 警报。 | ||
DataNode Service RPC 处理延迟(每小时) | 如果 DataNode 端口上的 RPC 处理延迟偏差在一个小时内超过200ms,则将触发 CRITICAL 警报。 | ||
NameNode Client RPC 处理延迟(每小时) | 如果 NameNode Client 端口上的 RPC 处理延迟偏差在一个小时内超过200ms,则将触发 CRITICAL 警报。 | ||
NameNode 堆使用增量情况(每天) | 如果 NameNode 堆使用量增量在一天之内超过了50%,则将触发 CRITICAL 警报。 | ||
DataNode Service RPC 处理延迟(每天) | 如果 DataNode 端口上的 RPC 队列延迟的偏差在一天之内超过了200ms,则将触发 CRITICAL 警报。 | ||
NameNode Client RPC 处理延迟(每天) | 如果 NameNode Client 端口上 RPC 队列延迟的偏差在一天之内超过了200ms,则将触发 CRITICAL 警报。 | ||
DataNode Service RPC 队列延迟(每天) | 如果 DataNode 端口上的 RPC 队列延迟的偏差在一天之内超过了200ms,则将触发 CRITICAL 警报。 | ||
NameNode Client RPC 队列延迟(每天) | 如果 NameNode Client 端口上 RPC 队列延迟的偏差在一天之内超过了200ms,则将触发 CRITICAL 警报。 | ||
HDFS 存储容量使用增量情况(每天) | 如果 NameNode 存储容量使用量增量在一天内超过了50%,则会触发 CRITICAL 警报。 | ||
NameNode 堆使用增量情况(每周) | 如果 NameNode 堆使用量增量在一周内超过50%,则将触发 CRITICAL 警报。 | ||
HDFS 存储容量使用增量情况(每周) | 如果 NameNode 存储容量使用量增量在一周内超过50%,则会触发 CRITICAL 警报。 | ||
备用 NameNode 进程状态 | 如果 Secondary NameNode 端口无法访问,则触发 CRITICAL 警报 | ||
DataNode 进程状态 | 如果 DataNode 进程端口响应时间大于5s,触发 CRITICAL 警报 | ||
DataNode 容量使用情况 | 如果集群中任意一台 DataNode 上的存储容量占用超过 80%,则会触发 CRITICAL 警报 | ||
DataNode 堆使用情况 | 如果 DataNode 当前的堆内存使用量超过 90%,则会触发 CRITICAL 警报 | ||
HDFS待删除块健康状态 | 如果 HDFS 中待删除的块数超过 100000,则会触发 CRITICAL 警报。 | ||
警告 | NameNode 安全模式状态 | 如果 NameNode 当前处于安全状态,则触发 WARNING 警报。 | |
NameNode 容量使用情况 | 如果 NameNode 已使用容量达到总容量的 75%,则会触发 WARNING 警报 | ||
NameNode RPC 延迟状况 | 如果 NameNode RPC 延迟大于3000ms,则会触发 WARNING 警报 | ||
备用 NameNode 进程状态 | 如果 Secondary NameNode 端口访问返回 400 以上的响应码,则触发 WARNING 警报 | ||
DataNode 容量使用情况 | 如果集群中任意一台 DataNode 上的存储容量占用超过 75%,则会触发 WARNING 警报 | ||
DataNode 堆使用情况 | 如果 DataNode 当前的堆内存使用量超过 80%,则会触发 WARNING 警报 | ||
Hive | 严重 | Hive Metastore 进程状态 | 如果监听不到或者确认不了 Hive Metastore 进程是否正常,则会触发 CRITICAL 警报。 |
HiveServer2 进程状态 | 如果监听不到或者确认不了 HiveServer2 进程是否正常,则会触发 CRITICAL 警报。 | ||
Kafka | 严重 | Kafka Broker 进程状态 | 如果监听不到或者确认不了 Kafka Broker 进程是否正常,则会触发 CRITICAL 警报。 |
YARN | 严重 | ResourceManager 进程状态 | 如果监听不到或者确认不了 ResourceManager 进程是否正常,则会触发 CRITICAL 警报。 |
NodeManager 健康状况 | 如果 NodeManager 进程访问失败,或者是带回的节点健康信息并不健康,则触发 CRITICAL 警告。 | ||
ResourceManager RPC 延迟情况 | 如果 ResourceManager RPC 平均延迟时间超过 5000ms,则触发 CRITICAL 警报。 | ||
警告 | ResourceManager RPC 延迟情况 | 如果 ResourceManager RPC 平均延迟时间超过 3000ms,则触发 WARNING 警报。 | |
ZooKeeper | 严重 | ZooKeeper 进程状态 | 如果监听不到或者确认不了 ZooKeeper 进程是否正常,则会触发 CRITICAL 警报。 |
HBase | 严重 | HRegion 进程状态 | 如果监听不到或者确认不了 HRegion 进程是否正常,则会触发 CRITICAL 警报。 |
HMaster 进程状态 | 如果监听不到或者确认不了 HMaster 进程是否正常,则会触发 CRITICAL 警报。 | ||
MapReduce2 | 严重 | MapReduce2 HistoryServer 进程状态 | 如果监听不到或者确认不了 MapReduce2 HistoryServer 进程是否正常,则会触发 CRITICAL 警报。 |
History Server RPC 延迟情况 | 如果 History Server RPC 平均延迟时间超过 5000ms,则触发 CRITICAL 警报。 | ||
警告 | History Server RPC 延迟情况 | 如果 History Server RPC 平均延迟时间超过 3000ms,则触发 WARNING 警报。 | |
Impala | 严重 | Impalad 进程状态 | 如果监听不到或者确认不了 Impalad 进程是否正常,则会触发 CRITICAL 警报。 |
Statestored 进程状态 | 如果监听不到或者确认不了 Statestored 进程是否正常,则会触发 CRITICAL 警报。 | ||
Catalogd 进程状态 | 如果监听不到或者确认不了 Catalogd 进程是否正常,则会触发 CRITICAL 警报。 | ||
Kudu | 严重 | Kudu Master 进程状态 | 如果监听不到或者确认不了 KuduMaster 进程是否正常,则会触发 CRITICAL 警报。 |
Kudu TServer 进程状态 | 如果监听不到或者确认不了 KuduTServer 进程是否正常,则会触发 CRITICAL 警报。 | ||
ClickHouse | 严重 | Clickhouse 进程状态 | 如果监听不到或者确认不了 Clickhouse 进程是否正常,则会触发 CRITICAL 警报。 |
Trino | 严重 | Coordinator 进程状态 | 如果监听不到或者确认不了 Coordinator 进程是否正常,则会触发 CRITICAL 警报。 |
Worker 进程状态 | 如果监听不到或者确认不了 Worker 进程是否正常,则会触发 CRITICAL 警报。 | ||
Presto | 严重 | Coordinator 进程状态 | 如果监听不到或者确认不了 Coordinator 进程是否正常,则会触发 CRITICAL 警报。 |
Worker 进程状态 | 如果监听不到或者确认不了 Worker 进程是否正常,则会触发 CRITICAL 警报。 | ||
Doris | 严重 | BE 进程状态 | 如果监听不到或者确认不了 BE 进程是否正常,则会触发 CRITICAL 警报。 |
FE 进程状态 | 如果监听不到或者确认不了 FE 进程是否正常,则会触发 CRITICAL 警报。 | ||
StarRocks | 严重 | BE 进程状态 | 如果监听不到或者确认不了 BE 进程是否正常,则会触发 CRITICAL 警报。 |
FE 进程状态 | 如果监听不到或者确认不了 FE 进程是否正常,则会触发 CRITICAL 警报。 |
查看告警规则
点击告警规则名称,即可查看当前告警规则的配置信息,包含事件类型、通知方式等配置详情。
编辑告警规则
选择告警规则,点击右侧操作栏中的编辑按钮,可以在弹窗中修改规则名称、事件类型、严重等级及通知方式。点击确定按钮,即可生效。
删除告警规则
若不需要继续订阅某些告警,可以选择对应的告警规则,点击删除并确认,即可删除告警规则,取消订阅。
查看告警历史
若需要查看历史告警信息,可以点击 Tab 切换到告警历史查看历史的告警信息,包括发生时间以及告警信息详情等:
您可以在时间筛选框中,指定历史时间范围,查看指定时间内的告警历史信息。
您也可以在搜索框中,输入规则名称、事件类型等信息,来精确搜索告警历史。