1 导出概述
StarRocks支持四种方式导出数据:
| 导出方式 | 描述 | 支持的数据格式 | 支持的存储系统 |
|---|---|---|---|
| INSERT INTO FILES导出 | 使用INSERT语句导出StarRocks表或者查询结果。 | parquet | TOS/HDFS |
| Export | 通过StarRocks EXPORT语句导出数据。 | CSV | TOS/HDFS |
| 使用Spark Connector导出 | 通过Spark查询StarRocks表数据导出数据。 | Spark支持的任意格式 | Spark支持的任意地址,支持TOS/HDFS/JDBC等目的地 |
| 使用Flink Connector导出 | 通过Flink查询StarRocks表数据导出数据。 | Flink支持的任意格式 | Flink支持的任意地址,支持TOS/HDFS/JDBC等目的地 |
2 使用INSERT INTO FILES导出
注意
该方式仅支持StarRocks 3.2.x及以上版本。
不支持LargeInt类型的导出。
INSERT INTO FILES支持将查询结果写入外部存储系统,因此可以将StarRocks表通过该方式导出。支持的外部存储系统为HDFS或TOS。
2.1 语法
INSERT INTO FILES( "path" = "s3://bucketName/sr_export/", "format" = "parquet", "aws.s3.region" = "cn-beijing", "aws.s3.endpoint" = "https://tos-s3-cn-beijing.ivolces.com", "aws.s3.use_aws_sdk_default_behavior" = "false", "aws.s3.use_instance_profile" = "false", "aws.s3.access_key" = "xxx", "aws.s3.secret_key" = "yyy==", "compression" = "zstd", "single" = "true" ) SELECT * FROM tb_demo;
2.2 参数说明
| 参数 | 是否必填 | 说明 |
|---|---|---|
| path | 是 | 导出的数据路径,导出到TOS时路径为 |
| format | 是 | 输出的数据格式,当前仅支持parquet格式。 |
compression | 是 | 使用的压缩格式,
|
| max_file_size | 否 | 导出为多个文件时,单个文件的最大大小。支持配置默认值1GB。 |
| single | 否 | 是否导出到单个数据文件。默认为false。 |
| partition_by | 否 | 需要将导出的数据文件按某列分区时可以设置该属性。设置后,输出目录会根据partition_by指定的列的值输出到不同的子目录。 |
| aws.s3.access_key | 否 | 访问TOS的ak。 |
| aws.s3.secret_key | 否 | 访问TOS的sk。 |
| aws.s3.region | 否 | TOS桶所在的region。 |
| aws.s3.endpoint | 否 | TOS服务的S3兼容endpoint。 |
| aws.s3.enable_ssl | 否 | 访问TOS时是否使用ssl。 |
| aws.s3.use_instance_profile | 否 | 如果使用instance_profile模式访问TOS需指定为true。使用instance_profile模式时,无需指定ak,sk。 |
| aws.s3.enable_path_style_access | 否 | 是否使用path sytle访问模式。 |
2.3 示例
INSERT INTO FILES( "path" = "s3://bucketName/sr_export/", "format" = "parquet", "aws.s3.region" = "cn-beijing", "aws.s3.endpoint" = "https://tos-s3-cn-beijing.ivolces.com", "aws.s3.use_aws_sdk_default_behavior" = "false", "aws.s3.use_instance_profile" = "false", "aws.s3.access_key" = "xxx", "aws.s3.secret_key" = "yyy==", "compression" = "zstd", "single" = "true" ) SELECT * FROM tb_demo;
3 Export导出
3.1 参数配置
FE可配置导出相关的参数,用于控制导出任务超时等。
export_checker_interval_second:导出作业调度器的调度间隔。默认为 5 秒。。export_running_job_num_limit:正在运行的导出作业数量限制。如果超过这一限制,则作业在执行完snapshot后进入等待状态。默认为 5。可以在导出作业运行时调整该参数的取值。export_task_default_timeout_second:导出作业的超时时间。默认为 2 小时。可以在导出作业运行时调整该参数的取值。export_max_bytes_per_be_per_task:每个导出子任务在每个 BE 上导出的最大数据量,用于拆分导出作业并行处理。按压缩后数据量计算,默认为 256 MB。export_task_pool_size:导出子任务线程池的大小,即线程池中允许并行执行的最大子任务数。默认为 5。
3.2 操作步骤
3.2.1 提交导出作业
语法:
EXPORT TABLE <table_name> [PARTITION (<partition_name>[, ...])] [(<column_name>[, ...])] TO <export_path> [opt_properties] WITH BROKER [broker_properties]
示例:
EXPORT TABLE demo.tb_demo (c1, c2, c3, c4, c5, c6) TO "s3a://bucketName/sr_export/" PROPERTIES ( "column_separator"=",", "load_mem_limit"="2147483648" ) WITH BROKER ( "aws.s3.region" = "cn-beijing", "aws.s3.endpoint" = "https://tos-s3-cn-beijing.ivolces.com", "aws.s3.use_aws_sdk_default_behavior" = "false", "aws.s3.use_instance_profile" = "false", "aws.s3.access_key" = "xxx", "aws.s3.secret_key" = "yyy==" );
3.2.2 查看导出作业
使用SHOW EXPORT可以查看已经提交的导出作业及状态。
语法:
SHOW EXPORT [ FROM <db_name> ] [ WHERE [ QUERYID = <query_id> ] [ STATE = { "PENDING" | "EXPORTING" | "FINISHED" | "CANCELLED" } ] ] [ ORDER BY <field_name> [ ASC | DESC ] [, ... ] ] [ LIMIT <count> ]
示例:
MySQL [demo]> SHOW EXPORT FROM demo; +-------+--------------------------------------+-----------+----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------+---------------------+---------------------+------------+---------+----------+ | JobId | QueryId | State | Progress | TaskInfo | Path | CreateTime | StartTime | FinishTime | Timeout | ErrorMsg | +-------+--------------------------------------+-----------+----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------+---------------------+---------------------+------------+---------+----------+ | 10329 | 3f0fe574-e100-11ee-821b-00163e5b1b2a | FINISHED | 100% | {"partitions":["*"],"column separator":",","columns":["c1","c2","c3","c4","c5","c6"],"tablet num":6,"broker":"","coord num":1,"db":"demo","tbl":"tb_demo","row delimiter":"\n","mem limit":2147483648} | s3a://bucketName/sr_export/ | 2024-03-13 14:09:26 | 2024-03-13 14:09:28 | NULL | 7200 | NULL | +-------+--------------------------------------+-----------+----------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-------------+---------------------+---------------------+------------+---------+----------+
3.2.3 查看导出作业的状态
SHOW EXPORT可以指定WHERE子句来查看特定QueryId或特定状态的导出作业执行情况。
SHOW EXPORT WHERE queryid = "b560e5fa-e100-11ee-821b-00163e5b1b2a";
3.2.4 取消导出作业
当需要取消导出作业时,可以通过CANCEL EXPORT语句取消正在执行的导出作业。
语法:
CANCEL EXPORT [FROM db_name] WHERE QUERYID = "query_id"
示例:
CANCEL EXPORT WHERE queryid = "b560e5fa-e100-11ee-821b-00163e5b1b2a";
注意
只支持取消正在运行中的导出作业。
取消时需要有对应表的EXPORT权限。
4 Spark Connector导出
使用Spark可以查询StarRocks中存储的数据,从而可以导出StarRocks中的数据。
4.1 基本原理
Spark Driver向StarRocks FE获取table的相关meta信息,包含要查询的tablet列表,tablet所在的BE地址等。然后Spark Executor向对应的BE发起rpc请求,获取tablet的数据。
暂时无法在飞书文档外展示此内容
4.2 前置条件
StarRocks表已存在
Spark集群与StarRocks集群网络连通
4.3 使用示例
4.3.1 Spark SQL
- 在Spark SQL中创建StarRocks view
spark-sql> CREATE TEMPORARY VIEW tb_starrocks USING starrocks OPTIONS ( "starrocks.table.identifier" = "demo.tb_demo", "starrocks.fe.http.url" = "<fe_host>:<fe_http_port>", "starrocks.fe.jdbc.url" = "jdbc:mysql://<fe_host>:<fe_query_port>", "starrocks.user" = "test", "starrocks.password" = "xxx" );
- 运行INSERT语句导出StarRocks表数据
dest_table可以是Spark支持的任意表,根据存储路径不同,存储系统可以是HDFS或TOS。
spark-sql> INSRT INTO dest_table SELECT * FROM tb_starrocks;
4.3.2 Spark DataFrame
- 运行spark shell,执行以下语句
scala> val df = spark.read.format("starrocks") .option("starrocks.table.identifier", s"demo.tb_demo") .option("starrocks.fe.http.url", s"<fe_host>:<fe_http_port>") .option("starrocks.fe.jdbc.url", s"jdbc:mysql://<fe_host>:<fe_query_port>") .option("starrocks.user", s"test") .option("starrocks.password", s"xxx") .load()
- 执行以下语句从StarRocks表中查询数据
根据需要存储的数据格式选择csv, json, parquet, orc等,路径可以设置为HDFS地址或者TOS地址。
scala> df.write.format("csv").save(filepath)
- 需要导出部分StarRocks数据时,可以在创建dataFrame时指定starrocks.filter.query
scala> val df = spark.read.format("starrocks") .option("starrocks.table.identifier", s"demo.tb_demo") .option("starrocks.fenodes", s"<fe_host>:<fe_http_port>") .option("user", "test") .option("password", "xxx") .option("starrocks.filter.query", "k=7 and dt='2022-01-02 08:00:00'") .load()
5 Flink Connector导出
StarRocks 提供自研的 Apache Flink® Connector (StarRocks Connector for Apache Flink®),支持通过 Flink 批量读取某个 StarRocks 集群中的数据。
5.1 基本原理
StarRocks的Flink Connector查询StarRocks数据时,由JobManger向FE获取query plan,然后由TaskManager向对应的BE发起rpc请求,获取tablet的数据。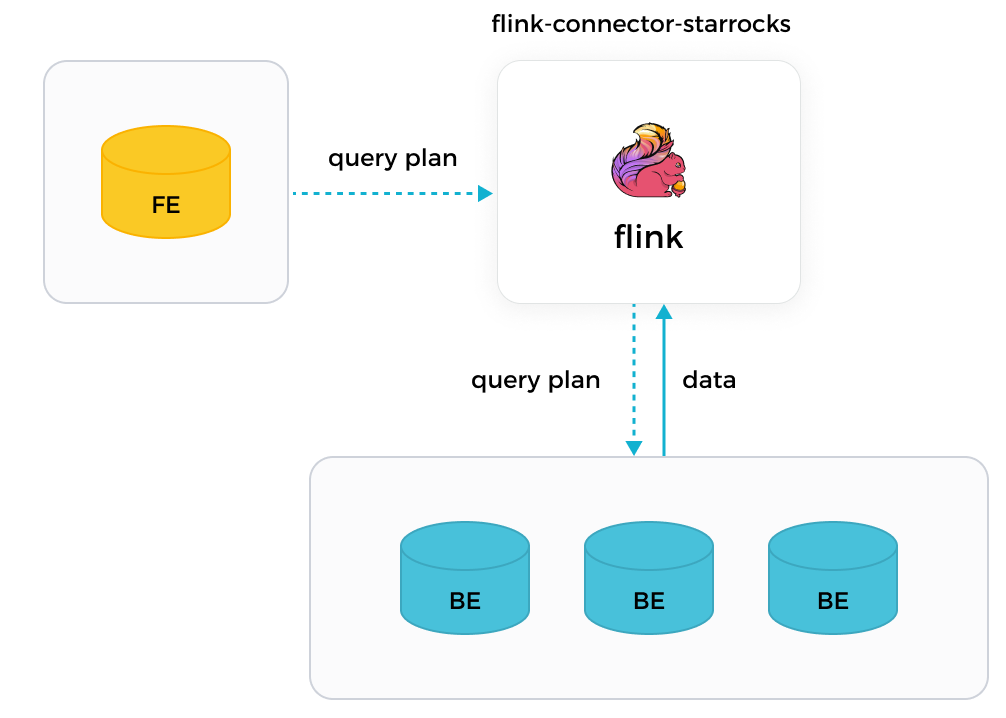
5.2 前置条件
StarRocks表已存在
Spark集群与StarRocks集群网络连通
5.3 使用样例
5.3.1 使用 Flink SQL 读取数据
- 在Flink SQL中创建StarRocks表
CREATE TABLE tb_sr_table ( `id` INT, `name` STRING ) WITH ( 'connector'='starrocks', 'scan-url'='192.168.xxx.xxx:8030', 'jdbc-url'='jdbc:mysql://192.168.xxx.xxx:9030', 'username'='xxxxxx', 'password'='xxxxxx', 'database-name'='test', 'table-name'='tb_demo' );
- 在Flink中查询StarRocks表数据
SELECT * FROM tb_sr_table;
- 使用INSERT语句导出StarRocks表至其他表中。
dest_table可以是Flink支持的任意表,根据存储路径不同,存储系统可以是HDFS或TOS。
INSERT INTO dest_table SELECT * FROM tb_sr_table;
5.3.2 使用 Flink DataStream 读取数据
- 使用Flink Connector创建StarRocksSource来查询数据
import com.starrocks.connector.flink.StarRocksSource; import com.starrocks.connector.flink.table.source.StarRocksSourceOptions; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.DataTypes; import org.apache.flink.table.api.TableSchema; public class StarRocksSourceApp { public static void main(String[] args) throws Exception { StarRocksSourceOptions options = StarRocksSourceOptions.builder() .withProperty("scan-url", "192.168.xxx.xxx:8030") .withProperty("jdbc-url", "jdbc:mysql://192.168.xxx.xxx:9030") .withProperty("username", "root") .withProperty("password", "") .withProperty("table-name", "tb_demo") .withProperty("database-name", "demo") .build(); TableSchema tableSchema = TableSchema.builder() .field("id", DataTypes.INT()) .field("name", DataTypes.STRING()) .build(); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.addSource(StarRocksSource.source(tableSchema, options)).setParallelism(5).print(); env.execute("StarRocks flink source"); } }