数据导入是指将原始数据按照业务需求进行清洗、转换、并加载到火山引擎 StarRocks 中的过程。
本文为您介绍数据的不同导入方式,本文图片来源于开源StarRocks的导入总览。。
1 背景信息
StarRocks 通过导入作业实现数据导入,每个导入作业都有一个标签 (Label),基于标签的唯一性,提供“至多一次 (At-Most-Once) ”语义。
StarRocks 提供了多种导入方式,您可以根据数据量大小或导入频率等要求选择最适合自己业务需求的导入方式。StarRocks 导入方式与各数据源关系图如下。
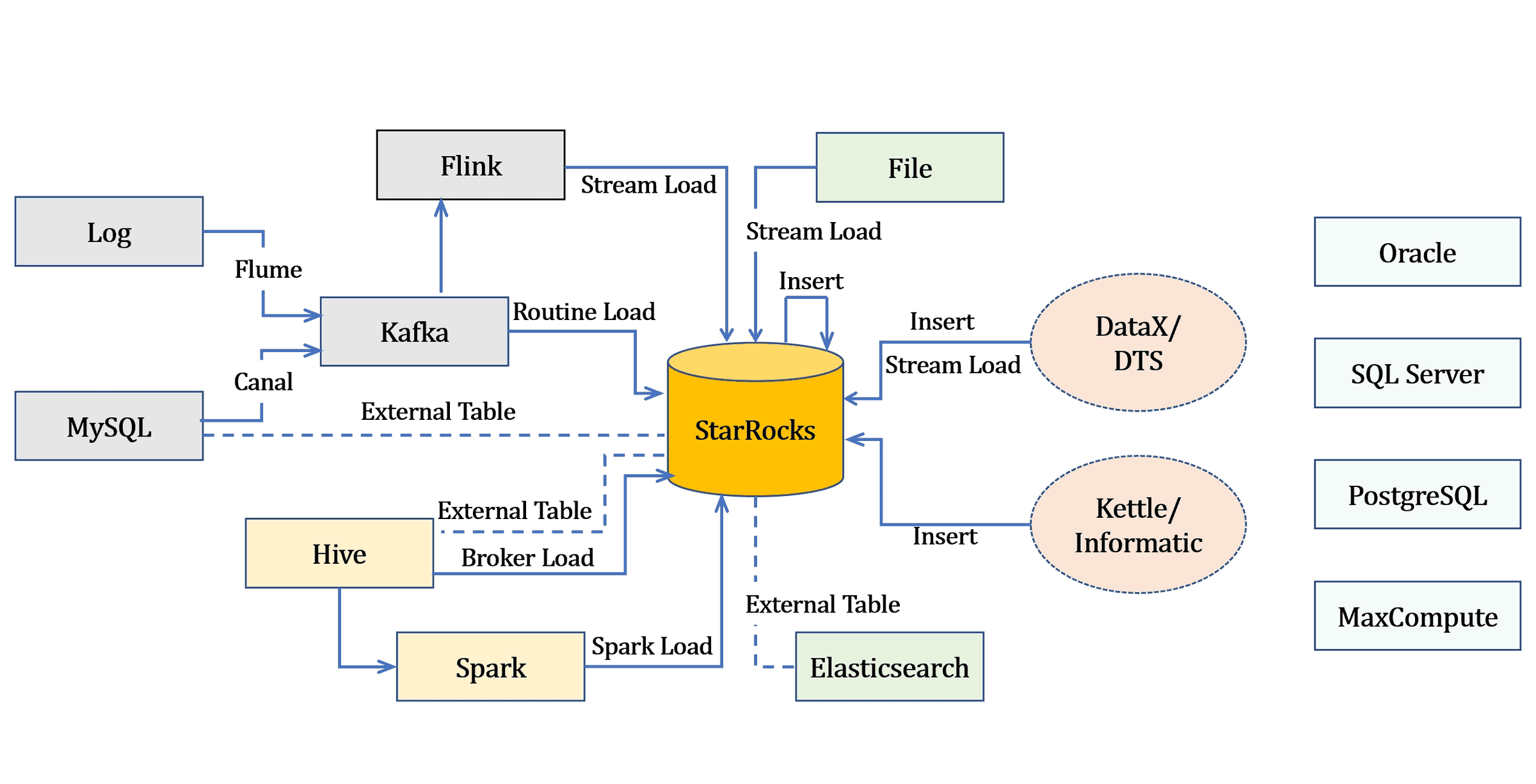
您可以根据不同的数据来源选择不同的导入方式:
| 场景 | 描述 |
|---|---|
实时数据导入 | 日志数据和业务数据库的 Binlog 同步到 Kafka 后,推荐使用 Routine Load 实现导入。但是如果导入过程中有复杂的多表关联和 ETL 预处理,建议先使用 Apache Flink 对数据进行处理,然后再通过 flink-connector-starrocks 导入到 StarRocks 中。 |
离线数据导入 | 数据源是 Hive 或 HDFS,推荐使用 Broker Load。如果需要导入的表较多时,如从 Hive、Iceberg、Hudi、Delta Lake 导入数据时,推荐创建 Hive catalog、Iceberg catalog、Hudi Catalog、Delta Lake Catalog,然后使用 INSERT 实现导入。 |
从另外一个 StarRocks 集群或从 Elasticsearch 导入数据时 | 推荐创建 StarRocks 外部表或 Elasticsearch 外部表,然后使用 INSERT 实现导入。 说明 StarRocks 外表只支持数据写入,不支持数据读取。 |
| MySQL 数据导入 | 推荐创建 MySQL 外部表、然后使用 INSERT 实现导入。如果要导入实时数据,建议您参考 从 MySQL 实时同步 实现导入。 |
| StarRocks 内部导入 | 推荐使用 INSERT 实现导入。 |
| 本地文件 | 推荐使用 Stream Load。 |
2 导入方式
StarRocks 提供 Stream Load、Broker Load、 Routine Load、Spark Load 和 INSERT 多种导入方式,满足您在不同业务场景下的数据导入需求。
StarRocks导入数据的模式分为同步导入和异步导入两种模型,不同导入方式采用的导入模型也不相同。
2.1 导入方式介绍
导入方式 | 描述 | 支持数据源 | 数据量 | 数据格式 | 同步模式 | 协议 |
|---|---|---|---|---|---|---|
Stream Load | 您可以通过 HTTP 协议发送请求将本地文件或数据流导入到 StarRocks 中,并等待系统返回导入的结果状态,从而判断导入是否成功。 |
| 10 GB 以内 |
| 同步 | HTTP |
Broker Load | 通过 Broker 进程访问并读取外部数据源。 |
| 数十到数百 GB |
| 异步 | MySQL |
Routine Load | 提供了一种自动从指定数据源进行数据导入的功能。通过 MySQL 协议提交导入作业,生成一个常驻线程,不间断的从数据源中读取数据并导入到 StarRocks 中 | Apache Kafka | 微批导入 MB 到 GB 级 |
| 异步 | MySQL |
| INSERT INTO SELECT | 外表导入。StarRocks 数据表之间的数据导入。 | StarRocks 表外部表 | 跟内存相关 | StarRocks 表 | 同步 | MySQL |
| INSERT INTO VALUES | 单条批量小数据量插入。通过 JDBC 等接口导入。 | 程序 ETL 工具 | 简单测试用 | SQL | 同步 | MySQL |
2.2 导入模型介绍
StarRocks 支持两种导入模式:同步导入和异步导入。
说明
如果是外部程序接入StarRocks 的导入功能,需要先判断使用导入方式是哪类,然后再确定接入逻辑。
同步导入
同步导入是指您创建导入作业以后,StarRocks 同步执行作业,并在作业执行完成以后返回导入结果。您可以通过返回的导入结果判断导入作业是否成功。支持同步模式的导入方式有 Stream Load 和 INSERT。
操作步骤:- 用户(外部系统)创建导入任务。
- StarRocks 返回导入结果。
- 用户(外部系统)判断导入结果。如果导入结果为失败,则可以再次创建导入任务。
异步导入
异步导入是指您创建导入作业以后,StarRocks 直接返回作业创建结果。
如果导入作业创建成功,StarRocks 会异步执行导入作业。但作业创建成功并不代表数据导入已经成功。您需要通过语句或命令来查看导入作业的状态,并且根据导入作业的状态来判断数据导入是否成功。
如果导入作业创建失败,可以根据失败信息,判断是否需要重试。
操作步骤:
创建导入作业。
根据 StarRocks 返回的作业创建结果,判断作业是否创建成功。
如果作业创建成功,进入下方步骤 3。
如果作业创建失败,可以回到上方步骤 1,尝试重试导入作业。
轮询查看导入作业的状态,直到状态变为 FINISHED 或 CANCELLED。
2.3 支持的数据类型
StarRocks 基本上支持导入所有数据类型:
| 类型 | 描述 |
|---|---|
| 整型类 | TINYINT、SMALLINT、INT、BIGINT、LARGEINT |
| 浮点类 | FLOAT、DOUBLE、DECIMAL |
| 日期类 | DATE、DATETIME |
| 字符串类 | CHAR、VARCHAR |
3 使用说明
3.1 内存限制
您可以通过设置参数来限制单个导入作业的内存使用,以防止导入占用过多的内存而导致系统 OOM。也避免设置过小的内存限制影响导入效率,因为内存使用量达到上限而频繁地将内存中的数据刷出到磁盘。
不同的导入方式限制内存的方式略有不同,具体请参见 Stream Load、Broker Load、Routine Load、Spark Load 和 INSERT。
注意
一个导入作业通常都会分布在多个 BE 上执行,这些内存参数限制的是一个导入作业在单个 BE 上的内存使用,而不是在整个集群上的内存使用总和。
您还可以通过设置一些参数来限制在单个 BE 上运行的所有导入作业的总的内存使用上限。可参考下面“通用系统配置”章节。
3.2 通用系统配置
本节解释对所有导入方式均适用的参数配置。
FE 配置
以下配置属于 FE 的系统配置,可以通过 FE 的配置文件 fe.conf 来修改。
参数 描述 max_load_timeout_second
导入超时时间的最大、最小值,单位均为秒。默认的最大超时时间为 3 天,默认的最小超时时间为 1 秒。
自定义的导入超时时间不能超过这个最大、最小值范围。该参数配置适用于所有模式的导入作业。min_load_timeout_second desired_max_waiting_jobs
等待队列可以容纳的导入作业的最大个数,默认值为 1024 。
如果 FE 中处于 PENDING 状态的导入作业数目达到最大个数限制时,FE 会拒绝新的导入请求。该参数配置仅对异步执行的导入有效。max_running_txn_num_per_db
每个数据库中正在进行的导入事务的最大个数(不区分导入类型、统一计数),默认值为 100。
当数据库中正在运行的导入事务达到最大值,后续提交的导入作业不会执行。如果是同步的导入作业,作业会被拒绝;如果是异步导作业,作业会在队列中等待。label_keep_max_second
导入任务记录的保留时间。
已经完成、且处于 FINISHED 或 CANCELLED 状态的导入作业记录在 StarRocks 系统的保留时长,默认值为 3 天。该参数通用于所有类型的导入任务。BE 配置
以下配置属于 BE 的系统配置,可以通过BE的配置文件 be.conf 来修改。
参数 描述 push_write_mbytes_per_sec
BE 上单个 Tablet 的最大写入速度,默认值为 10 MB/s。
根据表结构 (Schema) 的不同,通常 BE 对单个 Tablet 的最大写入速度大约在 10 MB/s 到 30 MB/s 之间。可以适当调整该参数的取值来控制导入速度。write_buffer_size
导入的数据在 BE 上会先写入一个内存块,当内存块大小达到阈值以后,才会写回磁盘。默认阈值为 100 MB。
阈值过小,可能会导致 BE 上存在大量的小文件,影响查询的性能。
阈值过大,可能会导致 RPC 超时,可以配合下面参数的
tablet_writer_rpc_timeout_sec一起调整。
tablet_writer_rpc_timeout_sec
导入过程中,发送一个 Batch(1024行)的 RPC 超时时间。默认为600秒。
RPC 可能涉及多个分片内存块的写盘操作,所以可能会因为写盘导致 RPC 超时,可以适当地调整这个超时时间。如果调大参数write_buffer_size,也需要适当地调大tablet_writer_rpc_timeout_sec。streaming_load_rpc_max_alive_time_sec
在导入过程中,StarRocks 会为每个 Tablet 开启一个 Writer 进程,用于接收和写入数据,该参数指定了 Writer 进程的等待超时时间,默认为 600 秒。
如果在参数指定时间内 Writer 进程没有收到任何数据,StarRocks 系统会自动销毁这个 Writer 进程。当系统处理速度较慢时,Writer 进程可能长时间接收不到下一批次数据,导致上报 "TabletWriter add batch with unknown id" 错误。可适当调大这个参数的取值。load_process_max_memory_limit_bytes
分别用于导入的最大内存和最大内存使用百分比,用来限制单个 BE 上所有导入作业的内存总和的使用上限。系统会在两个参数中取较小者,作为最终的使用上限。
load_process_max_memory_limit_bytes:默认为 100 GB。
load_process_max_memory_limit_percent:表示 BE 总内存限制的百分比,默认为 30%。
load_process_max_memory_limit_percent
4 常见问题
数据导入过程中可能会遇到的异常及解决方案,详见导入常见问题。