E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南RayRayCluster 使用使用Ray进行词频统计(WordCount)
E-MapReduce组件操作指南RayRayCluster 使用使用Ray进行词频统计(WordCount)

本章节介绍下使用Ray进行词频统计(Word Count)的示例。
1 简介
MapReduce是一种分布式计算模型,将大型数据集的处理分解为三个阶段:
Map(映射)阶段:对数据集中的元素应用指定的函数进行转换或映射,产生键值对,其中键代表一个元素,值是为该元素计算的度量。
Shuffle**(洗牌)阶段**:收集Map阶段的所有输出,并按键组织它们。如果多个计算节点上出现相同的键,这个阶段包括在不同节点之间传输或洗牌数据。
Reduce(归约)阶段:对Shuffle阶段的元素进行聚合。每个单词的出现次数总和是每个节点上出现次数的总和。
2 使用指导
首先定义两个函数:
map_task:这个函数接收一段文本作为输入,然后统计这段文本中每个单词出现的次数。它使用一个字典word_counts来保存每个单词及其出现的次数。reduce_task:这个函数用于合并多个map_task任务的结果。它接收多个字典作为输入(即每个map_task的输出),并将它们合并成一个包含所有单词及其总出现次数的单一字典。
并行处理文本数据:使用列表推导式和
map_task.remote()方法,为每段文本创建了一个Ray任务,并将它们提交给Ray运行时进行并行处理接下来合并处理结果:使用
reduce_task.remote(*map_results),将所有map_task的结果作为参数传递给reduce_task,以并行方式合并这些结果。最后获取并打印结果:使用
ray.get(reduce_result)获取reduce_task的执行结果。整体样例代码
wordcount.py文件内容;
import ray # 初始化Ray ray.init() # 定义一个Ray任务 @ray.remote def map_task(text): # 统计词频 word_counts = {} for word in text.split(): if word in word_counts: word_counts[word] += 1 else: word_counts[word] = 1 return word_counts # 定义另一个Ray任务 @ray.remote def reduce_task(*word_counts_list): # 合并词频统计结果 word_counts = {} for word_counts_dict in word_counts_list: for word, count in word_counts_dict.items(): if word in word_counts: word_counts[word] += count else: word_counts[word] = count return word_counts # 文本数据 texts = ['hello world', 'world world', 'hello hello world'] # 使用Ray任务并行处理文本数据 map_results = [map_task.remote(text) for text in texts] # 使用Ray任务合并处理结果 reduce_result = reduce_task.remote(*map_results) # 获取并打印结果 result = ray.get(reduce_result) print(result)执行上述python代码
ray job submit --working-dir . -- python wordcount.py查看执行结果:
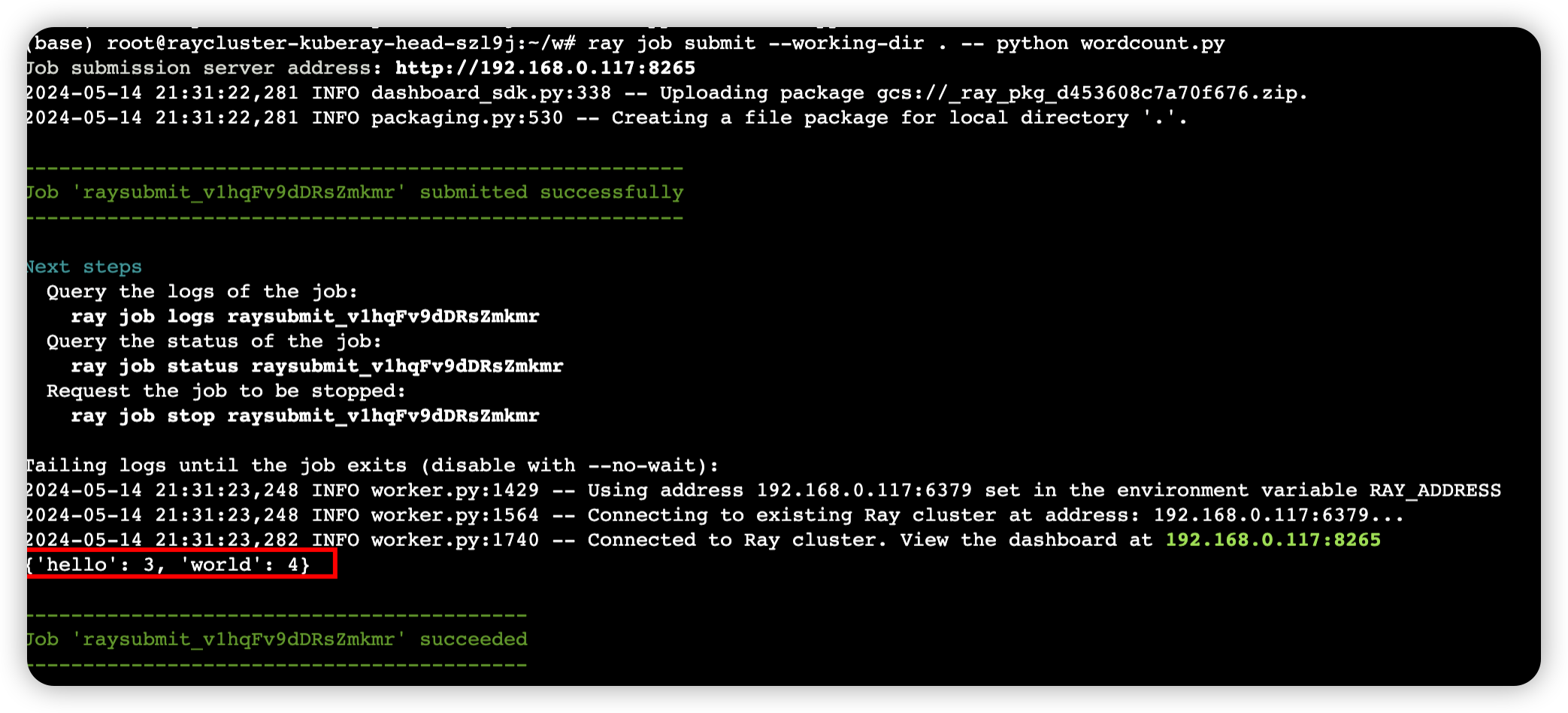
总结:这个用例展示了Ray框架如何简化分布式计算任务的实现。通过将计算分解为多个小任务(Map阶段),然后并行地在多个核心或节点上执行这些任务,最后合并结果(Reduce阶段),Ray能够有效地处理大规模数据集。这种方法在大数据处理和分布式机器学习中非常常见。