使用火山引擎 E-MapReduce(简称“EMR”),提供包年包月和按量计费两种付费类型。成本取决于实例类型、存储类型和存储大小。本章向您介绍如何优化火山引擎 EMR 集群,并利用弹性伸缩和 EMR Stateless 等功能来降低成本。
1 成本优化
火山引擎 EMR 提供了各种功能来帮助降低成本。为了充分利用这些特性,需考虑以下因素。
1.1 负载类型
您可以在火山引擎 EMR 上运行不同的应用程序和工作负载类型。
对于仅运行了特定时间段的应用程序,您可以使用瞬态 EMR 集群,其基于火山引擎 EMR Stateless 云原生开源大数据平台提供极致的弹性能力,您可以快速的创建和释放集群,并查看历史作业信息等。
对于长时间运行的应用程序,您可以使用长时间运行的集群。
1.2 实例类型
大部分的火山引擎 EMR 集群可以运行在通用型 ECS 机型上(g2i 和 g1ie 机型)。计算密集型集群可以从计算型实例(c2i 和 c1ie)中获益。OLAP 集群和内存消耗型作业可以从内存型实例(r1ie)中获益。Master 节点通常没有大量计算需求,因此可以选择通用型机型。
1.3 存储类型
火山 EMR 集群支持对象存储 TOS(Tinder Object Storage)作为存储介质。火山引擎对象存储 TOS 是火山提供的海量、安全、低成本、易用、高可靠、高可用的分布式云存储服务。TOS 支持标准型、低频型、归档型三种存储类型,您可以根据数据冷热情况对数据分层优化存储成本。
2 存储优化
通过存储优化,可以提升作业的性能。这里有一些策略帮助您去优化集群存储。
数据分区
对数据进行分区并且基于分区读取数据时,查询只读取所需的文件。这减少了在查询过程中扫描的数据量。
文件大小
需要避免小文件过多的问题。小文件太多会增加 NameNode 压力,导致元数据膨胀、寻址索引速度变慢等问题。Hadoop 分析引擎处理大量小文件的速度远远慢于处理同等数据量的大文件的速度。每一个小文件都会占用一个 task,而 task 启动将耗费大量时间,造成作业的大部分时间都耗费在启动 task 和释放 task 上。您可以登录集群,使用 hadoop -fs count 命令统计文件数。
hadoop fs -count /datadir/xxx/xxxx数据压缩
数据压缩,可以减少数据的存储空间,减少 HDFS 读入的字节,这意味着读取数据的时间会减少。 对于提升作业执行的性能有所帮助。
存储格式
Parquet 和 ORC 是一种基于列的存储格式,Apache Avro 是一种基于行的存储格式。基于列的存储格式对只查询数据中部分列的查询请求是最佳选择,如果查询所有列可以选择基于行的存储格式 。Parquet和ORC比Avro提供更好的压缩比。
3 计算优化
在前面的章节中,我们介绍了存储成本和性能优化。下面我们将介绍一些功能和方法去优化火山引擎 EMR 的计算。
弹性伸缩
EMR 提供弹性伸缩(Auto Scaling)能力,根据您的业务需求和策略,自动的调整计算资源的管理服务。当您在使用 EMR 集群过程中,如果经常出现波峰波谷的情况,那么,在计算高峰时自动扩展一部分临时计算能力帮助渡过业务计算高峰,渡过业务高峰后再进行自动缩容,可以降低用户的计算资源使用成本。
EMR 支持时间和负载两种弹性伸缩规则。详情参考配置弹性伸缩。
Stateless
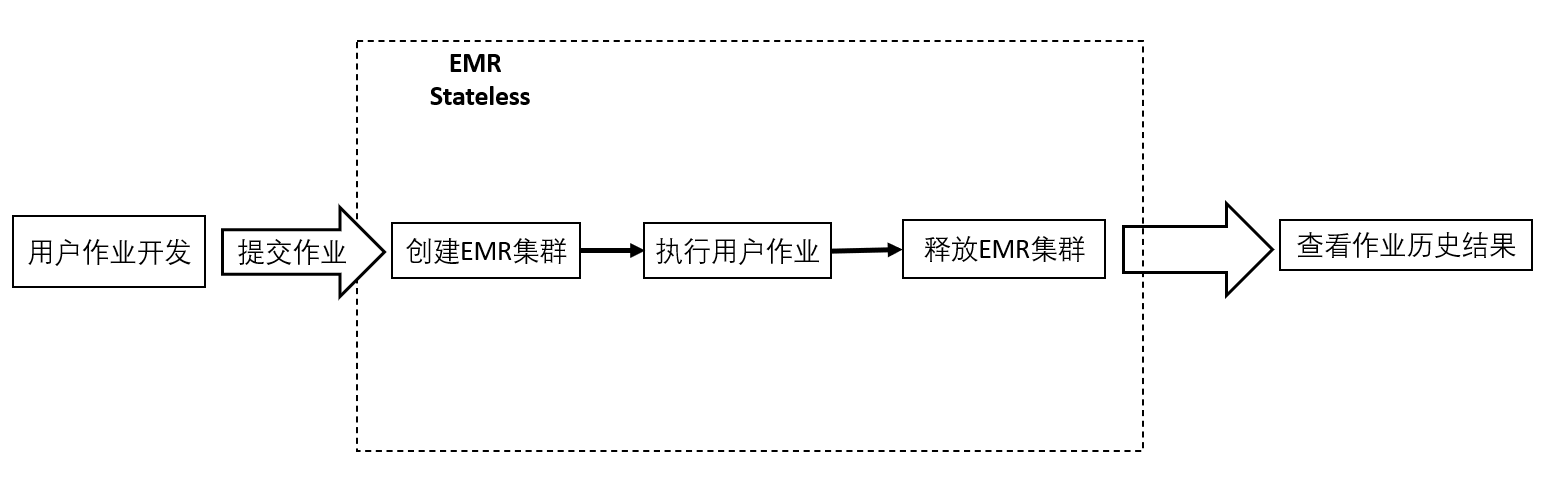
EMR Stateless 将状态数据如用户数据、权限数据、Hive 元数据、日志数据、弹性规则外置,让长运行集群变成轻量级瞬态集群,从创建集群等待任务运行,到任务开始和结束触发集群的创建和释放,从而获得更好的弹性、扩展性、安全性,让数据平台架构有更好的演进成长能力和最佳的成本优化。瞬态集群极大满足用户在组件版本升级、极致成本优化等日益增长的诉求。
EMR Stateless 允许集群随您作业的提交而启动,随作业的结束而释放,将长时间运行的集群变成轻量级的瞬态集群,您只需为运行期间的集群资源付费,极大优化了计算成本。
4 后续操作
成本评估和优化完成后,接下来将为您介绍数据迁移的操作。详见数据迁移。