E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南ProtonProton 概述
E-MapReduce组件操作指南ProtonProton 概述

1 介绍
Proton 是火山引擎 E-MapReduce(EMR)团队推出的,针对存算分离场景提供的加速引擎,其深度优化的 TOS 访问能力、 JobCommitter 功能 和 缓存能力,可极大地提升计算任务的执行效率。
1.1 存算分离 vs 存算一体
Hadoop 大数据组件(包括 Hive、Spark、Yarn、HBase、 Presto/Trino 等)总体上是基于 HDFS 标准 API来访问底层分布式文件系统。我们将存储服务(HDFS)和计算服务(Yarn)部署在一套集群的方案称为存算一体方案,将存储服务切换到火山引擎对象存储服务(TOS) 的方案称为存算分离方案。
HDFS 集群(即存算一体方案)相比TOS(存算分离方案)有一些明显的不足:
- HDFS 集群对存储资源使用多,对计算资源使用少。用户一般会将计算组件和 HDFS 组件混合部署在同一批节点上,达到充分复用存储和计算资源的目的,但这会使集群的存储能力和计算能力深度耦合。
举例来说,某业务拥有1PB的数据,而一周才跑一次离线计算,采用 Hadoop 混部意味着用户需要为这1PB数据支付昂贵的计算资源费用。采用存算分离模式,用户只需支付1PB数据的存储费用和少量计算资源费用即可,大大减少成本开支。 - 用户需要为 HDFS 集群提前预留空闲存储空间(例如预留30%左右的闲置空间供未来使用),而火山引擎 TOS 是按需付费,用户不需要为预留存储资源付费。
- 开源版本的 HDFS 冷数据存储(HDFS Erasure Coding)能力,使用和维护门槛较高,维护冷数据到自建 HDFS 集群对运维人员的挑战较大。而火山引擎对象存储服务的冷数据存储能力经历公司内外部场景磨炼,相对成熟。根据 TOS 定价文档可以看出,冷归档存储容量费用(即冷数据存储)相比标准存储容量费用单价低很多。因此,对于低频访问的大体量冷数据,用户可借助云上 TOS 冷数据存储能力大幅降低存储成本。
TOS 对象存储服务在给 Hadoop 大数据用户带来诸多便利和成本优化的同时,同样存在一些挑战:
- TOS 对象存储的 Rename 操作比较耗时,且原子性语义不容易保证。
- TOS 对象存储的 List 操作相对 HDFS 比较耗时。
火山引擎 EMR 内置的 Proton 组件比较好地解决了上述问题,使得用户可以很方便地将 Hadoop 大数据生态平滑地从自建 HDFS 集群迁移到云上 TOS 对象存储服务。下面为您介绍 Proton 无缓存模式、有缓存模式的基本概念及它们的异同点。
1.2 无缓存模式
无缓存模式的proton组件只包含一个SDK jar包,被放置在hadoop classpath下。它通过实现 HDFS标准API,将对文件系统的访问映射为对TOS的访问。同时针对大数据分析场景,深度优化了 TOS 读写能力。在离线场景下,采用 Proton 无缓存模式的读写性能可以做到和自建 HDFS 性能持平。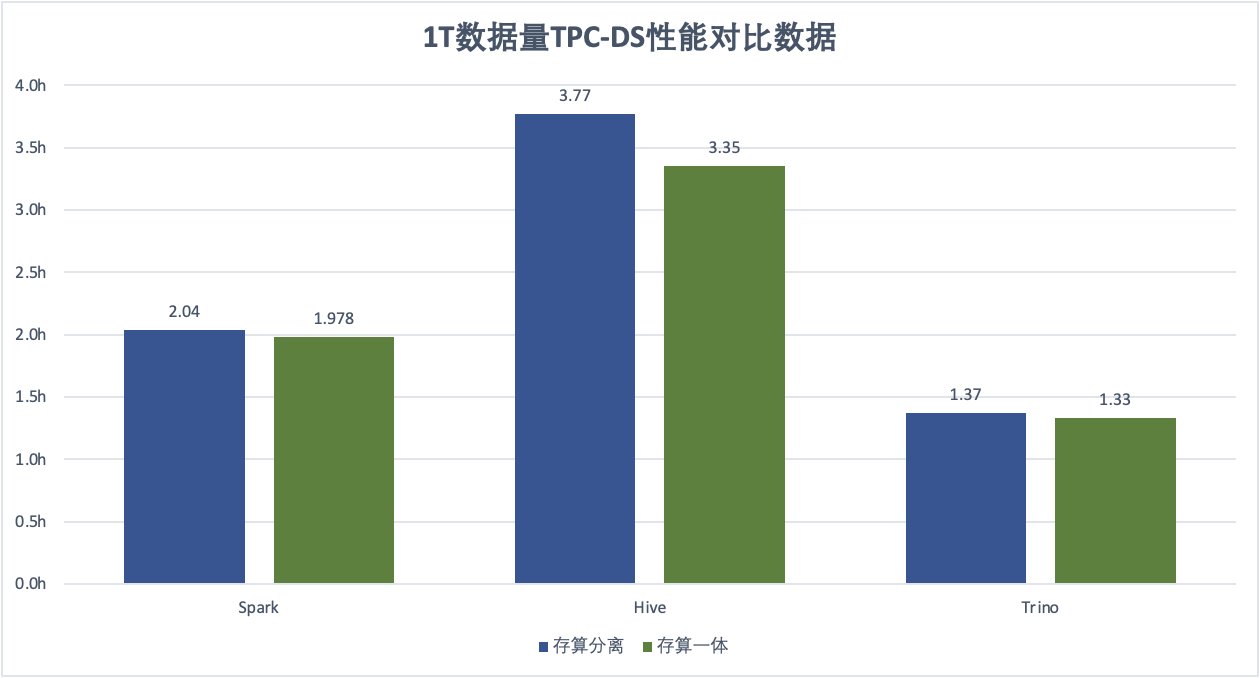
针对常见分析引擎(Hive、Spark、Presto/Trino) ,Proton 提供了深度优化的 Job Commiter 功能,使得其存算分离性能相比直接使用开源方案提升1倍。有关JobCommitter更多的介绍,请参考:火山EMR 存算分离JobCommitter最佳实践 。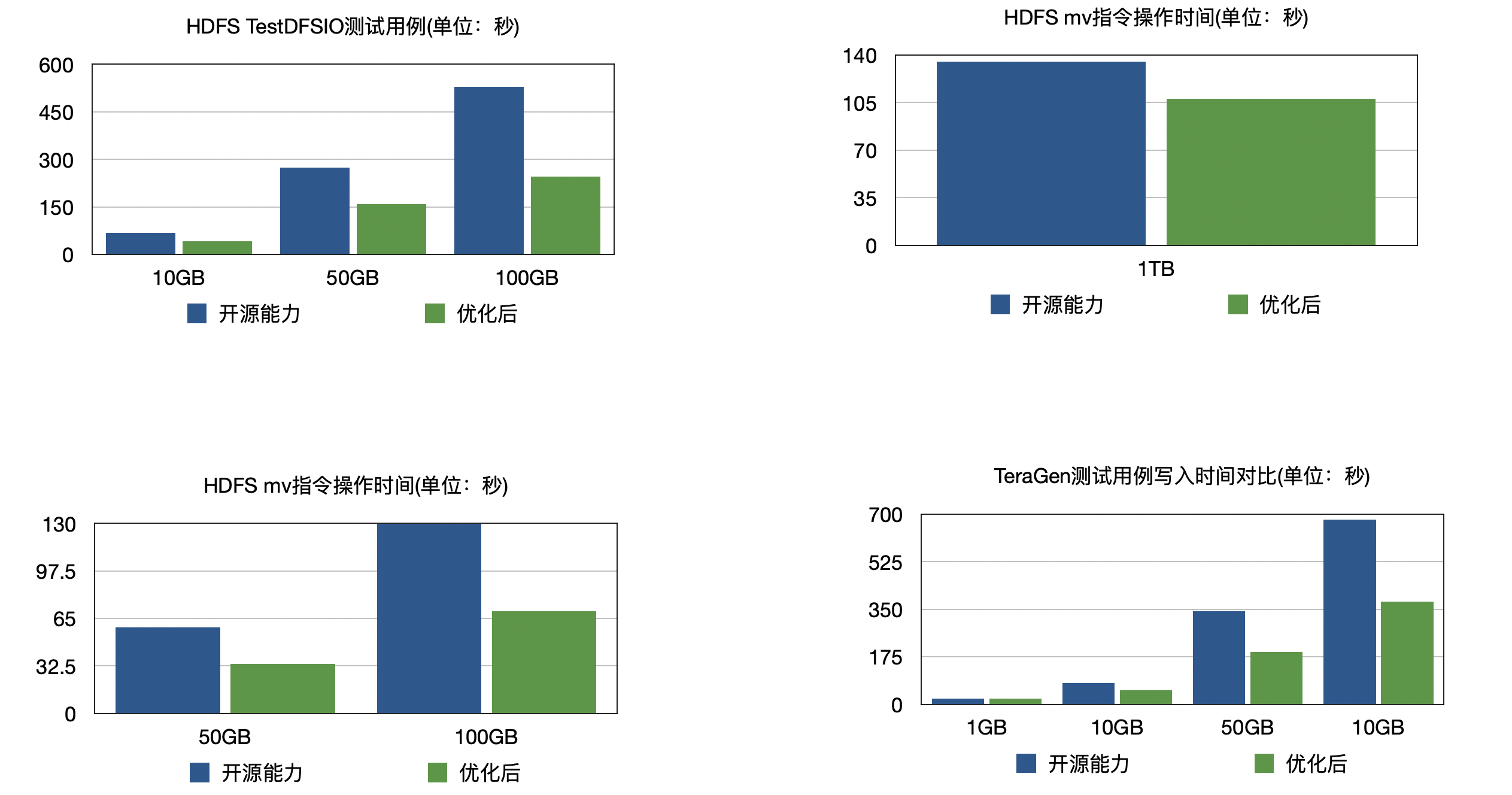
1.3 有缓存模式
除了无缓存模式外,Proton还提供有缓存模式,通过将元数据、数据缓存到EMR节点,可以获得比直接访问TOS更好的性能。无缓存模式和有缓存模式是兼容的,用户可以在两种模式间按需切换。
有缓存模式包括一组高可用的三副本MetaServer和若干个DataServer集合(在EMR集群上,默认将MetaServer节点部署在Master节点上,而将DataServer节点部署在Core节点上)。MetaServer负责缓存元数据,DataServer负责缓存TOS的对象数据,DataServer通过心跳与MetaServer沟通。在启用缓存加速后,用户的元数据请求会直接发送给MetaServer,数据IO请求则发给DataServer。以读数据为例,客户端首先会向MetaServer发送元数据请求,包含了要读取的文件路径,MetaServer向客户端返回文件对应blocks所在的DataServer地址。接着客户端会向DataServer发送数据IO请求,读取文件的数据。
1.4 两种模式对比
无缓存模式 | 有缓存模式 | |
|---|---|---|
存算分离 | 支持 | 支持 |
部署服务 | 不需要额外部署 | 需要部署MetaServer、DataServer |
资源需求 | 无 | 需要本地盘,推荐本地SSD |
认证方式 | AssumeRole、静态AKSK、环境变量AKSK | AssumeRole、静态AKSK、环境变量AKSK |
可用性 | 高 | 高,缓存服务不可用时自动fallback到TOS |
TOS请求次数 | 多 | 少 |
list性能 | 慢 | 快 |
读吞吐 | 低 |
|
2 版本说明
关于版本信息,请查看:Proton 发行版本
3 生态集成
Proton 目前支持 Hadoop MR、Hive、Spark、Flink 四种引擎类型,关于每种引擎如何配置,请参考链接文档:
- Hadoop: Hadoop 使用 Proton
- Hive: Hive 使用 Proton
- Spark: Spark 使用 Proton
- Flink: Flink使用 Proton
4 参数调优
Proton 提供了丰富的参数方便用户进行自主调优。对于 EMR 集群,用户可以在 EMR 集群控制台 > 集群详情 > HDFS 服务参数中进行配置,配置文件为 core-site.xml。如果是用户自建集群,可以在 core-site.xml 进行自主配置。
参数列表:Proton 参数配置
5 使用须知
创建EMR集群时,无论是否选择安装Proton服务,EMR集群都会集成无缓存模式需要的Proton SDK,当选择安装Proton服务后,默认开启有缓存模式。
开启有缓存模式后,EMR集群默认没法访问存储在TOS上的历史数据。如果要访问这些历史数据,需要先执行Load操作批量同步历史数据的元数据,或者开启元数据自动同步功能。具体操作请参考Proton元数据同步。