本文通过设计一个基本的 ETL 场景,关联到集群中各大主要的大数据组件,同时结合 Airflow 一些设计原则,助您进一步掌握 Airflow 的使用。
一般来说,编写一个 DAG 文件需要涉及两个主要部分:
通过编码创建 DAG 源文件,成为 Airflow 识别的工作流。
测试该文件,满足我们的预期。
1 前提条件
以下示例基于添加了 Airflow 服务的 Hadoop 类型集群,集群创建操作详见:创建集群。
2 工作流实现指引
2.1 正确定义 Airflow Task
Airflow 是一个编程式的工作流调度组件,给予我们自由度的同时,也附带着一些因实现不规范导致任务执行不符合预期的风险,下面通过一些说明指引您正确编写Task 逻辑。
我们应该像对待数据库领域中的事务一样去对待 Airflow 中的 task,这意味着一些不完整的数据不应该在任务结束时落到 HDFS 或 TOS 这样的地方。
Airflow 在一个 Task 运行失败时会自动重试,这个过程要求 Task 本身应该是“幂等”的,但不仅是输入不变时输出也应该一致,这里还要求输入本身也应该保持稳定。下面是一些有助于 Task 运行与重试时保持稳定的做法:
在任务定义时不要使用
INSERT,这可能导致在重试运行时带来一些重复行,用UPSERT来替代是一种更好的选择。为了保证输入稳定,最好在一个特定的分区进行读写。我们不应该在 Task 中读取最新的数据,在某次运行的重试前后如果数据发生了更新,那就会导致一个特定的 DAG Run 有不同的运行结果。我们推荐采用类似于
data_interval_start作为某次运行的特定分区,在有写出数据的操作时,也应当遵循这样的分区方法。避免使用类似于
datetime.datetime.now()这样的方法,特别是用它参与到一些关键的计算当中,会导致不同的输出。
为了保持 Airflow 环境的整洁,一些重复性的参数,比如说连接信息应该专门配置到 Airflow Connections 中,而非在每一个 DAG 中单独定义。而在每一个 DAG 中,专门定义一个
default_args来管理变量也是一种很好的实践,它们作用于该 DAG 的全局,所有的 Operator 都可以复用,排版会更简洁更易读。
2.2 任务间通信
在 EMR Airflow 中,DAG 中定义的任务是分散在集群中不同节点上运行的,这意味着如果我们有一些希望跨任务使用的数据,需要有一个全局的存储来交换,不能通过简单的约定一个目录,落盘到本地,然后不同的任务读取该文件来实现。
面对跨任务通信的场景,Airflow 提供了XCom组件,它致力于在一个工作流的上下游交换一些 小体积 的信息。一个比较好的实践是,如果您流程中有一份比较大的数据产出,下游需要使用,可以将这些数据放置到 HDFS 组件(Hadoop 类型默认必选,Presto/Trino 类型集群可选安装)中,或者是 TOS,然后通过XCom将该文件的路径信息传给下游使用。
在与其他组件交互的过程中可能涉及到一些认证信息,这些信息不应该编码在 DAG 当中,最好将其配置在 Airflow Connections 中,Airflow 会承诺连接信息的安全可靠,然后在 DAG 中通过 Connection Id 来引用它们。
2.3 正确编写 DAG 顶层代码
让我们先回顾一个机制,Airflow Scheduler 中,会以定义的min_file_process_interval为时间间隔,对 DAG 源文件做一次执行,这个更新机制,保证了 Airflow 中的工作流定义与实际源文件描述的保持一致。
Scheduler 的这次执行过程,本质是运行了一遍 DAG 文件中除了 Operator 的具体逻辑以外的代码。一个影响本次执行效率的重要因素就是该文件顶层代码的设计,并且也往往被忽视,这里的原则是,除了定义 DAG 结构所必需的逻辑以外,服务于具体 Operator 运行所需的逻辑都不应该在顶层代码中定义,而是在对应的具体过程的 Scope 中进行定义。
简单举一些不好的顶层代码的例子:在顶层代码中引入一个重量级模块,进行数据库连接(比如使用 Airflow Variables,它会从数据库中读取对应变量值),进行 http 请求等等。这些代码与 DAG 结构无关,却在 Scheduler 解析并更新 DAG 结构的时候显著提高了处理时间。
下面是两个来自官方的例子说明:
2.3.1 反例
from datetime import datetime from airflow import DAG from airflow.operators.python import PythonOperator import numpy as np # <-- THIS IS A VERY BAD IDEA! DON'T DO THAT! with DAG( dag_id="example_python_operator", schedule_interval=None, start_date=datetime(2021, 1, 1), catchup=False, tags=["example"], ) as dag: def print_array(): """Print Numpy array.""" a = np.arange(15).reshape(3, 5) print(a) return a run_this = PythonOperator( task_id="print_the_context", python_callable=print_array, )
2.3.2 正例
from datetime import datetime from airflow import DAG from airflow.operators.python import PythonOperator with DAG( dag_id="example_python_operator", schedule_interval=None, start_date=datetime(2021, 1, 1), catchup=False, tags=["example"], ) as dag: def print_array(): """Print Numpy array.""" import numpy as np # <- THIS IS HOW NUMPY SHOULD BE IMPORTED IN THIS CASE a = np.arange(15).reshape(3, 5) print(a) return a run_this = PythonOperator( task_id="print_the_context", python_callable=print_array, )
2.4 简化DAG
虽然 Airflow 做了很多性能上的优化工作,被设计成为一个可以支持很多 DAG 与 Task 运行的调度组件,但是从根本来说,一个 Airflow 服务能不能做到高效运转,还是要取决于实际负载,也就是在 Airflow 中调度运行的 DAG 自身的复杂度。
衡量 DAG 是否足够简单是没有一个明确的指标来定义的,从本质上讲看待 DAG 就应该和看待其他 Python 代码文件一样,有一些通用的原则评价代码质量是否足够高。而从 Airflow 本身出发,有一些特定的原则可以指导我们编写出更精简的 DAG 源文件:
正如在前文 正确编写 DAG 顶层代码 中提到的,一个 DAG 文件的顶层代码设计应该要只与结构定义相关。
定义工作流逻辑,要尽可能的保持线性,如
A->B->C结构,避免庞杂的分支系统,这可以显著提升 Airflow 的调度性能,无论是在解析还是具体调度运行阶段。尽可能保持一个文件与一个 DAG 相对应。在 Airflow 2.x 版本,有针对在一个源文件中定义多个 DAG 对象的场景进行专门的优化,但如果我们能做到将多个 DAG 对象分拆到各自独立的文件中仍然是比较好的做法,一方面每个文件的解析处理时间会下降,并且它们的处理可以负载到多个不同的 FileProcessor 中去运行,这种并行处理可以从整体上降低处理时间。
3 场景说明
您的生产集群在运行过程中,在某些场景下会产生一个格式化的数据文件 stu.txt,持久化在集群的 HDFS 中,但您不确定具体产生的时间。
stu.txt 存在,需要被 load 录入 Hive 表,作为处理前的数据源。
录入的数据需要被 Spark 读取出来,进一步转化处理。
4 具体实现
4.1 数据源
101,'CAI',3RD,'USA',usa 102,'ANTO',10TH,'ENGLAND',usa 103,'PRABU',2ND,'INDIA',usa 104,'KUMAR',4TH,'USA',usa 105,'JEKI',2ND,'INDIA',usa
4.2 过程
数据文件的感知与读取
这样的需求需要使用到 HdfsSensor,用以感知 HDFS 中某文件是否存在。
解析录入 Hive 表
这里使用 HiveOperator 来进行建表与 load 操作。
Spark 读取转化
基于 load 的数据源,执行 spark 任务进行处理,可以使用 SparkSqlOperator 与 SparkSubmitOperator。
from airflow import DAG from airflow.operators.bash import BashOperator from airflow.providers.apache.hdfs.sensors.hdfs import HdfsSensor from airflow.providers.apache.hive.operators.hive import HiveOperator from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator from airflow.providers.apache.spark.operators.spark_sql import SparkSqlOperator from airflow.utils.dates import days_ago args = { 'owner': 'airflow', } with DAG( dag_id='emr_etl_case', default_args=args, schedule_interval='30 10 * * *', start_date=days_ago(2), tags=['example'], ) as dag: prepare_file = BashOperator( task_id='raw_file_generate', bash_command=''' cat << EOF > ~/stu.txt 101,'CAI',3RD,'USA',usa 102,'ANTO',10TH,'ENGLAND',usa 103,'PRABU',2ND,'INDIA',usa 104,'KUMAR',4TH,'USA',usa 105,'JEKI',2ND,'INDIA',usa EOF ''' ) put_file = BashOperator( task_id='put_into_hdfs', bash_command = '''hadoop dfs -put -f ~/stu.txt /''' ) file_sensor = HdfsSensor( filepath="/stu.txt", task_id='detect_raw_file', hdfs_conn_id='hdfs_conn_id', poke_interval=10, timeout=5 ) table_create = HiveOperator( task_id='create_table_case', hive_cli_conn_id='hiveserver2_emr', schema='default', hql='''create table if not exists student( std_id int,std_name string,std_grade string,std_addres string) partitioned by (country string) row format delimited fields terminated by ','; ''' ) load_data = HiveOperator( task_id='load_data_case', hive_cli_conn_id='hiveserver2_emr', schema='default', hql='''load data inpath '/stu.txt' into table student partition(country='usa'); ''' ) spark_sql_case = SparkSqlOperator( task_id='spark_case', sql='''select * from student; ''', master='yarn', name='airflow-spark-sql-select' ) #spark_submit_case = SparkSubmitOperator( #) prepare_file >> put_file >> file_sensor >> table_create >> load_data >> spark_sql_case
5 测试
如果要将一个 DAG 实际投入生产,那么对应的测试工作必然是免除不了的。在 Airflow 中提供了多样的测试方法,从多维度衡量一个 DAG 的生产可用性。
5.1 DAG Loader 测试
这是一个最基本的测试,每一个 DAG 编写完成后都需要先确认能不能被 Airflow 正确识别,在与 Airflow 实际运行时保持一致的环境中(比如对应的venv环境中),运行
python my_dag.py
即可进行 DAG 文件的快速检查。
这里如果结合 Linux 内建的 time 工具,还可以进行 DAG 文件解析耗时的衡量,在对 DAG 代码文件优化的前后可以根据该结果来验证效果。
time python my_dag.py
以上的测试方式,会额外启动一个解释器,这是 Airflow 运行时所不需要的额外开销,可以通过加上-c选项来获得更接近于实际的解析耗时。
time python -c my_dag.py
5.1.1 DAG Loader 的单元测试示例
import pytest from airflow.models import DagBag @pytest.fixture() def dagbag(self): return DagBag() def test_dag_loaded(self, dagbag): dag = dagbag.get_dag(dag_id="emr_etl_case") assert dagbag.import_errors == {} assert dag is not None assert len(dag.tasks) == 6
5.2 测试 DAG 的 DAG
这个说法可能有点奇怪,但确实是一种可用的方式。在我们实际的工作流中,可能会用到很多 Airflow 社区提供的 Provider 中的各个模块,针对这些模块去进行单元测试没有太多必要,因为社区已经向我们做出了保证。
这时候我们关心的结果可能是利用对应的 Operator 等模块组织起来的 Task,到底有没有如预期的运行。我们可以为这种任务运行单独编写 DAG,在对应的 Task 运行之后,会有一个负责检查的后续 Task(比如各种 Sensor)。
示例:
put_file_in_hdfs = BashOperator(...) file_sensor = HdfsSensor( filepath="/your_expect_path", task_id='detect_file', hdfs_conn_id='hdfs_conn_id', poke_interval=10, timeout=5 ) put_file_in_hdfs >> file_sensor
5.3 预发布环境测试
如果可能的话,在正式上生产之前,最好有一个与生产环境对齐的预发布环境来完整测试运行 DAG 文件。为了配合这种多环境的运行,最好保证 DAG 中涉及到参数的读取等与环境相关的操作都是参数化而非硬编码的,避免在切换不同环境的时候还需要去修改 DAG 中的代码定义。
import os deployment = os.environ.get("DEPLOYMENT", "PROD")
6 Airflow 扩容适配
6.1 背景
Airflow 工作流的正常运行,需要参与调度的机器上持有该工作流对应的 DAG 文件。在弹性扩缩容等场景下,对于新扩的节点,如果其上有 Airflow Worker 组件,则需要进行工作流文件分发,否则会造成调度到其上的工作流无法运行。
6.2 解决方案
对于节点的扩缩,EMR 提供了引导操作的能力,可以在新节点加入时,对应组件部署的前后插入脚本执行。我们可以采用组件部署后的策略,在新节点上来进行工作流文件的获取。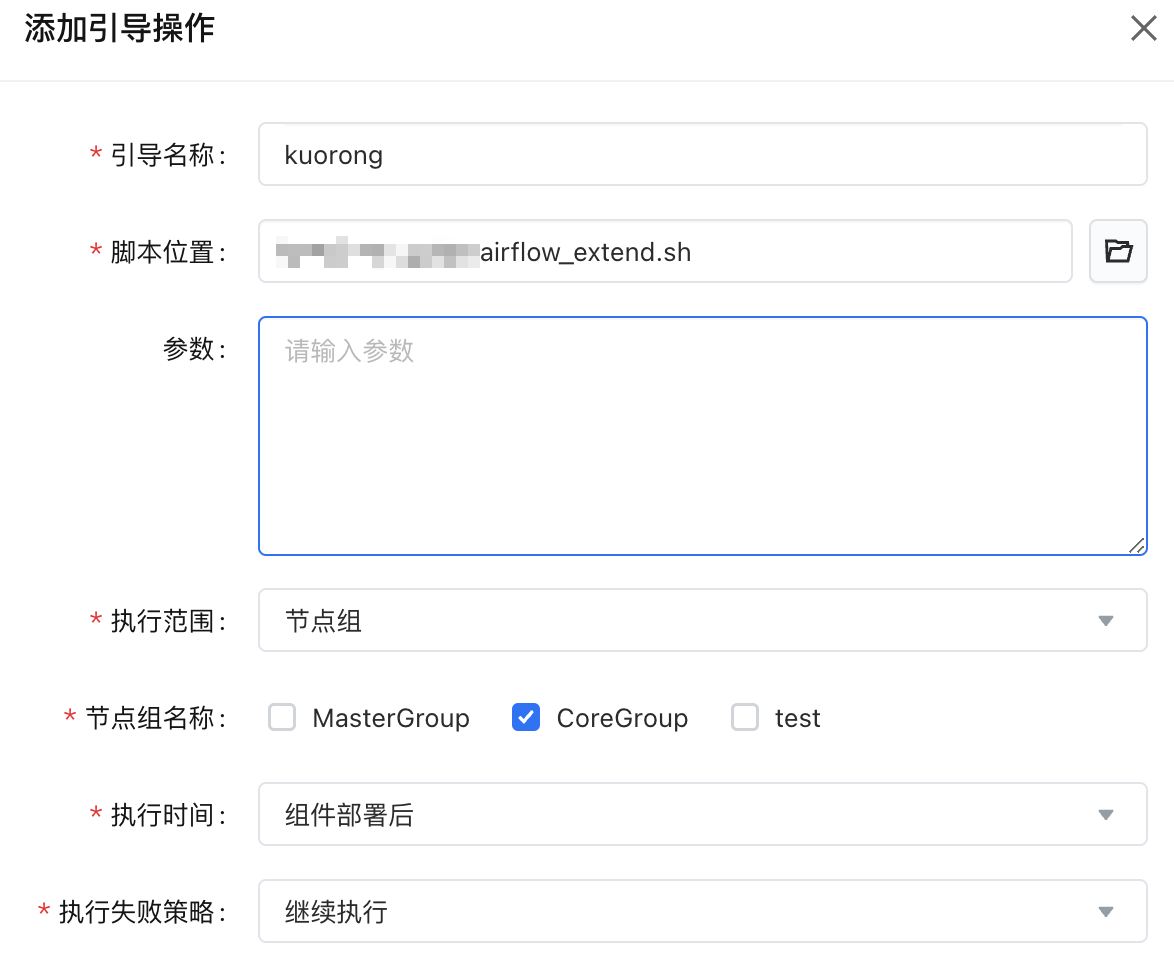
下面是一个供参考的同步工作流定义的脚本:


#!/usr/bin/env bash # 假设您的所有工作流定义都在 emr-master-1 机器上, dag_folder 配置为 /usr/lib/emr/current/airflow/dags mkdir /usr/lib/emr/current/airflow/dags scp -o "StrictHostKeyChecking no" -r emr-master-1:/usr/lib/emr/current/airflow/dags/* /usr/lib/emr/current/airflow/dags chown -R airflow:airflow /usr/lib/emr/current/airflow/dags