导航
E-MapReduce
搜索目录或文档标题搜索目录或文档标题
产品动态与公告
产品简介
发行版本
EMR on ECS
发行版本
版本说明
EMR 3.x版本
EMR-3.6.X 版本说明
EMR-3.4.X 版本
EMR 2.x版本
EMR 1.x版本
EMR 1.3.x版本
产品计费
快速入门
EMR on ECS 操作指南
集群管理
集群配置
集群监控
EMR on VKE 操作指南
EMR Serverless 操作指南
EMR Serverless 队列
EMR Serverless 实例(OLAP)
操作指南
数据湖查询(StarRocks)
性能调优
组件操作指南
MapReduce2
Hive
Spark
Spark(仅适用于EMR on VKE形态)
Spark(仅适用于EMR Serverless Spark形态)
Presto(仅适用于Serverless形态)
Knox
OpenLDAP
Ranger
HBase
Phoenix
Tez
Iceberg
StarRocks
数据湖分析
最佳实践
Proton
基础使用
高阶使用
Livy
Celeborn
Celeborn(仅适用于EMR on VKE形态)
Ray(仅适用于EMR on VKE及EMR Serverless形态)
Raycluster使用
最佳实践
EMR on ECS最佳实践
EMR on VKE最佳实践
开发参考
API 参考
EMR on ECS API参考
集群管理
节点组管理
用户管理
用户组管理
应用管理
EMR on VKE API参考
集群管理
应用管理
EMR Serverless API参考
SDK 参考
EMR on ECS SDK 参考
EMR Serverless SDK 参考
- 文档首页 /E-MapReduce/组件操作指南/Hive/概述
概述
最近更新时间:2023.07.12 10:25:15首次发布时间:2021.09.01 17:27:34
我的收藏
有用
有用
无用
无用
文档反馈
Hive 是一款基于 Hadoop 的数据仓库架构,可以通过 HiveQL(类 SQL 语言)对分布式存储中的大型数据集进行提取、转化和加载(ETL)操作,以及元数据管理。
关于Hive的的更多的介绍,可以参考Apache Hive官网。
1 Hive 组件说明
基本组件介绍如下:
| 名称 | 说明 |
|---|---|
| Hive Client | Hive Client 是 Hive 客户端,提供 Beeline、JDBC 应用所需的驱动包,通过该客户端可以向 HiveServer2 提交SQL作业。 |
Hive MetaStore | Hive MetaStore 是 Hive 元数据管理模块,该模块将 database、table、column 等元数据信息存储到数据库中。 |
| HiveServer2 | HiveServer2 HiveQL 查询服务器,接收来自 JDBC 客户端提交的 SQL 请求,对 SQL 语句进行编译、解析成对应的 MapReduce 任务或者 HDFS 操作,从而完成数据的提取、转换、分析。同时支持多客户端并发以及身份验证。一个集群内可部署多个 HiveServer,提供负载均衡能力。 |
2 Hive 原理
Hive 作为 Hadooop 生态的数据仓库,主要能力是对 HiveQL 进行编译、解析,生成并执行相应的作业。HiveQL 操作请参考:HiveQL语言手册。
Hive的结构见图: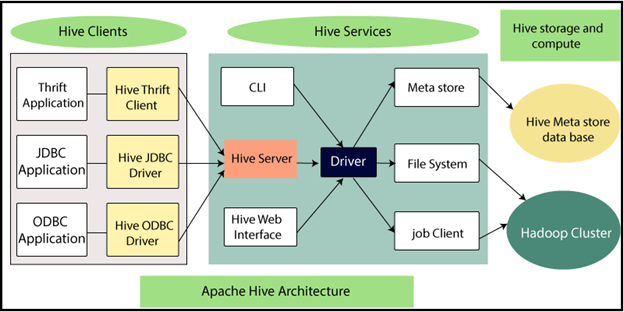
Meta Store: 对元数据进行读写和更新操作。
JDBC: 客户端连接方式。
Hive Server: 提供 Thrift 接口,作为 JDBC 连接的服务端,接收 HiveQL 请求,交由 Driver 执行,并将结果返回客户端。
Driver: 管理 HiveQL 执行的整个生命周期。通过 Compiler 编译转化为一系列相互依赖的 Map/Reduce 任务,并经过 Optimizer 优化器对其优化,最后由 Executor 执行器进行执行。
3 版本功能介绍
下面为您介绍火山引擎 E-MapReduce(简称EMR)各版本对应的 Hive 组件版本,以及各版本中 Hive 提供功能限制。更多组件版本介绍详见:版本概述说明。
| EMR版本 | Hive组件版本 | 功能介绍 |
|---|---|---|
| 1.2.1 | 3.1.2 | 支持 Tez 和 MR 计算引擎。默认是 Tez |
| 1.3.0 | 3.1.2 | 支持 Tez 和 MR 计算引擎。默认是 Tez |
| 1.3.1 | 3.1.2 | 支持 Tez 和 MR 计算引擎。默认是 Tez |
| EMR版本 | Hive组件版本 | 功能介绍 |
|---|---|---|
| 2.0.1 | 2.3.9 | 支持 Tez 和 MR 计算引擎。默认是 Tez |
| 2.1.0 | 2.3.9 | 支持 Tez 和 MR 计算引擎。默认是 Tez |
| EMR版本 | Hive组件版本 | 功能介绍 |
|---|---|---|
| 3.0.1 | 3.1.2 | 支持 Tez 和 MR 计算引擎。默认是 Tez |
| 3.1.0 | 3.1.2 | 支持 Tez 和 MR 计算引擎。默认是 Tez |