E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南RayRayCluster 使用Ray中Placement Group 使用指导
E-MapReduce组件操作指南RayRayCluster 使用Ray中Placement Group 使用指导

Placement Group是Ray中的一个特性,它允许用户在集群中以原子方式预留资源,即要么所有的资源都被成功预留,要么一个都不预留,不会出现只预留了部分资源的情况。这对于确保有足够的资源来运行特定的任务或actor集合非常有用。
Placement Group由一组资源束(bundles)组成,每个资源束代表一组需要预留的资源。用户可以指定每个资源束的大小和类型。如下,创建一个资源束:{"CPU": 1, "GPU": 1},代表1个CPU和1个GPU。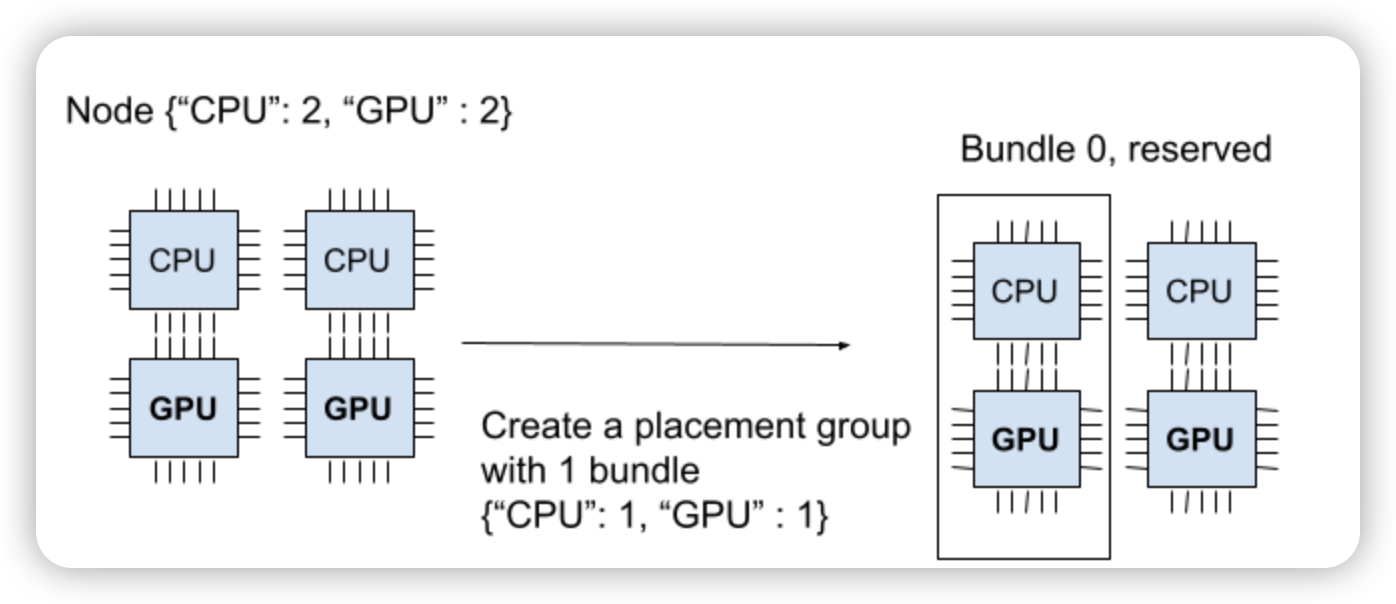
一个资源束不能跨节点创建的,也就是需要的资源,必须在一个节点上完整满足。如上图,创建
{"CPU": 9},是不会调度到这个节点上。已经创建
{"CPU": 1, "GPU": 1}的资源束,这时再创建{"CPU": 2, "GPU": 2}就会处于pending状态。
1 适用场景
紧密协作的task和 actor:对于需要频繁通信或共享状态的任务和 actor,将它们放在同一个 Placement Group 中可以减少通信延迟和提高整体效率。
资源密集型任务:对于需要大量特定资源(如 GPU)的任务,使用 Placement Group 可以确保这些任务能够获得所需的资源,并且不会与其他任务竞争这些资源。
多租户环境:在多租户环境中,可能需要将不同用户的作业隔离在不同的节点上。使用 Placement Group 可以根据用户或作业的标签来分配资源。
性能测试和调优:通过将任务和 actor 分组并在特定的节点上运行,可以更容易地进行性能测试和调优,因为可以更精确地控制作业的运行环境。
故障隔离:通过将任务或actor分散到多个节点上,可以减少单个节点失败对整体应用的影响。可以通过使用SPREAD或STRICT_SPREAD策略来实现。
因此使用 Placement Group 时,需要考虑集群的资源分配、任务和 actor 的通信模式以及整体的性能目标。正确使用 Placement Group 可以更好地管理和优化 Ray 集群的资源使用,提高应用程序的性能和可靠性。
2 Placement Group 策略
在Ray中,Placement Group的策略用于指定资源束(bundles)在集群中的放置方式。以下是Ray支持的四种放置策略:
PACK:尽可能地将所有资源束打包到同一个节点上。如果一个节点无法满足所有资源束的需求,那么资源束会被分散到其他节点上。这是一种软策略,即使无法将所有资源束打包到同一个节点上,Placement Group的创建也不会失败。
SPREAD:这种策略会尽可能地将资源束分散到不同的节点上。如果集群的节点数少于资源束的数量,那么多个资源束可能会被放置到同一个节点上。这也是一种软策略,即使无法将所有资源束分散到不同的节点上,Placement Group的创建也不会失败。
STRICT_PACK:这种策略类似于PACK,但它是一种硬策略。如果一个节点无法满足所有资源束的需求,那么Placement Group的创建会失败。
STRICT_SPREAD:这种策略类似于SPREAD,但它也是一种硬策略。如果集群的节点数少于资源束的数量,那么Placement Group的创建会失败。
这些策略可以通过ray.util.placement_group函数的strategy参数来指定。通过合理地选择和使用这些策略,用户可以根据自己的需求来控制任务和actor在集群中的放置方式。
3 适用示例
- 创建 Placement Group
使用 ray.util.placement_group 模块创建一个 Placement Group,指定分组的资源标签和数量,以及是否将分组放置在同一个节点上。
from pprint import pprint import time # Import placement group APIs. from ray.util.placement_group import ( placement_group, placement_group_table, remove_placement_group, ) from ray.util.scheduling_strategies import PlacementGroupSchedulingStrategy # Initialize Ray. import ray head_ip = {xxx} head_port = {xxx} #默认是10001 # Initialize connection using existing ray clusters ray.init(address="ray://{}:{}".format(head_ip, head_port)) # OR create a single node Ray cluster. # ray.init(num_cpus=2, num_gpus=2) # Reserve a placement group of 2 bundles# that have to be packed on the same node. pg = placement_group([{"CPU": 1}, {"CPU": 1}], strategy="STRICT_PACK")
示例中head_ip和head_port需要填写RayCluster的地址。
示例中strategy="STRICT_PACK" 表示这些资源标签将被尽可能紧密地打包到可用的节点上。
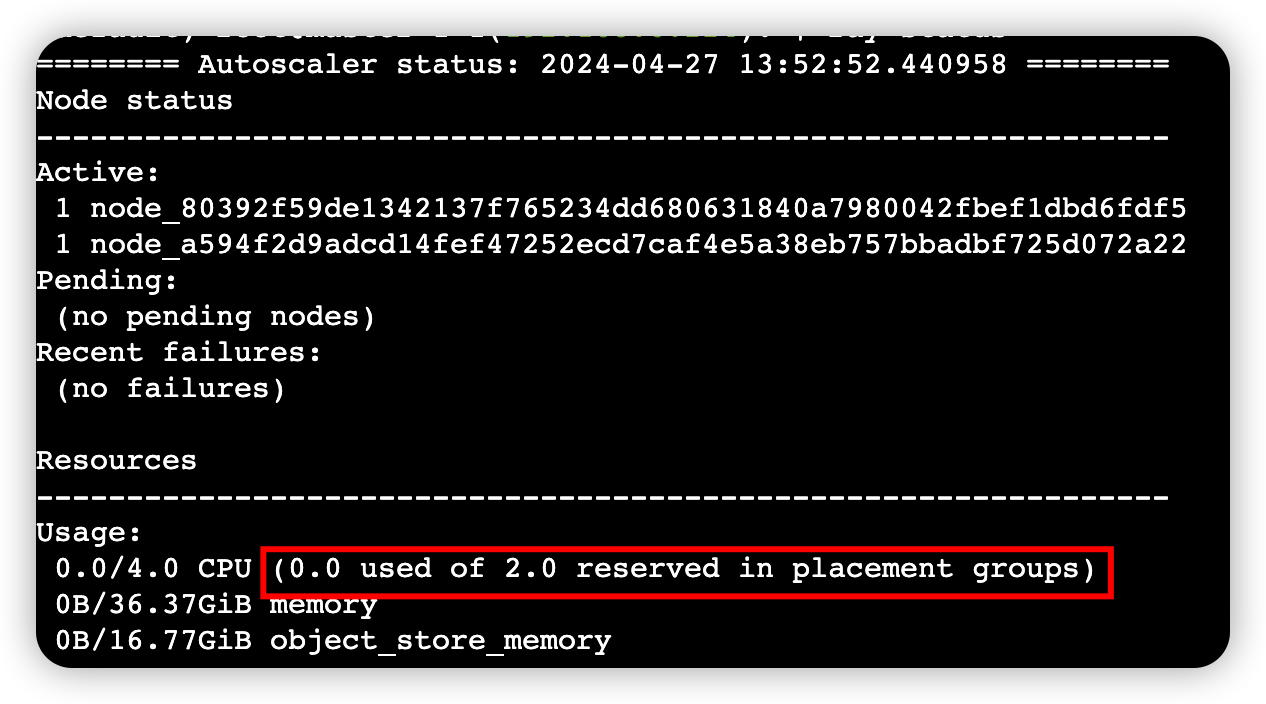
查看命令行工具
ray status,查看Placement Group的资源使用情况和调度资源需求ray status
将任务和 actor 绑定到 Placement Group
创建了 Placement Group 之后,将task和 actor 绑定到这个分组上。这意味着它们将只在 Placement Group 指定的节点上运行。
# 启动一个 actor,绑定到 Placement Group @ray.remote(num_cpus=1) class Actor: def __init__(self): pass def ready(self): pass # 启动 actor 实例并将其绑定到 Placement Group actor = Actor.options( scheduling_strategy=PlacementGroupSchedulingStrategy( placement_group=pg, ) ).remote() # 调度任务并将其绑定到 Placement Group ray.get(actor.ready.remote(), timeout=10)
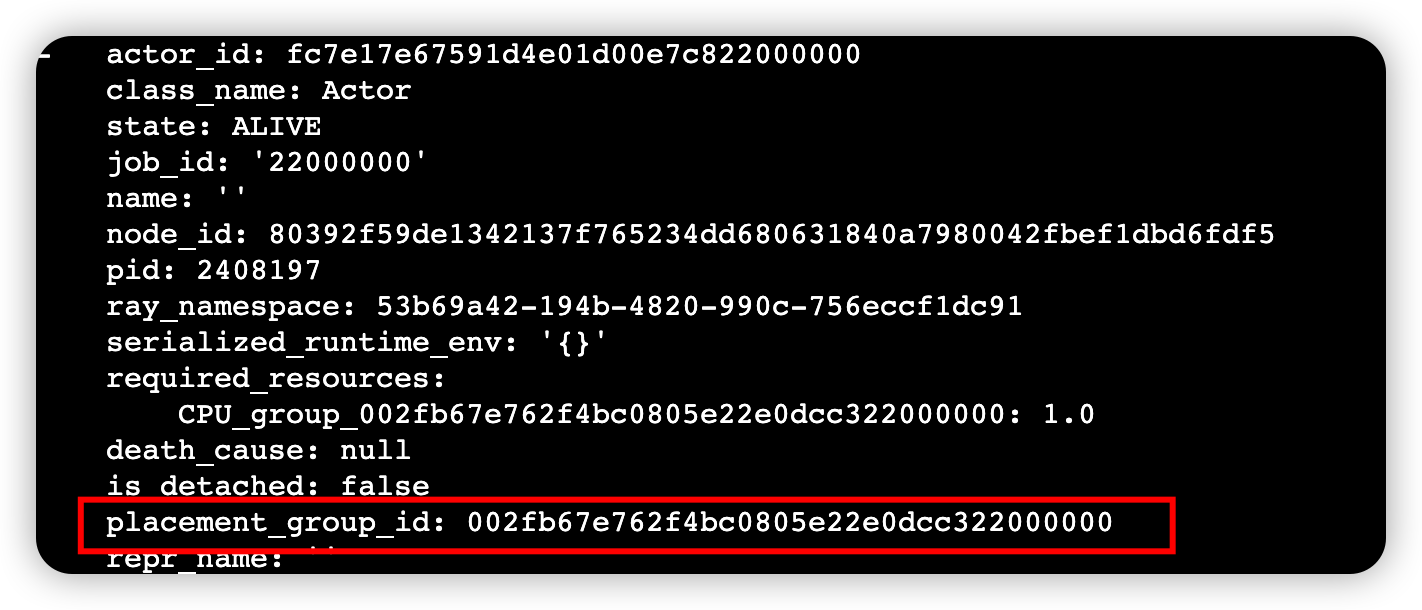
使用下面命令查看Actor的执行状态
ray list actors --detail
管理Placement Group
使用
ray.util.placement_group模块中的函数来管理 Placement Group,例如查询其状态或删除它。# 查询 Placement Group 的状态 print(placement_group_table(pg)) # 删除 Placement Group remove_placement_group(pg) # 等待placement group被kill. time.sleep(1) # 查询 Placement Group 的状态 pprint(placement_group_table(pg)) """ {'bundles': {0: {'CPU': 1.0}, 1: {'CPU': 1.0}}, 'bundles_to_node_id': {0: '80392f59de1342137f765234dd680631840a7980042fbef1dbd6fdf5', 1: '80392f59de1342137f765234dd680631840a7980042fbef1dbd6fdf5'}, 'name': '', 'placement_group_id': '002fb67e762f4bc0805e22e0dcc322000000', 'state': 'REMOVED', 'stats': {'end_to_end_creation_latency_ms': 1.649, 'highest_retry_delay_ms': 0.0, 'scheduling_attempt': 1, 'scheduling_latency_ms': 1.41, 'scheduling_state': 'REMOVED'}, 'strategy': 'STRICT_PACK'} """