导航
StarRocks行存表使用实践
最近更新时间:2024.02.18 19:03:00首次发布时间:2024.01.15 15:23:48
1 数据服务场景
行存表具有非常高的读写QPS,因此经常被用在ADS层,用作数据服务。
作为数据服务使用的时候,必须指定主键查询范式,案例如下:
CREATE TABLE ads_table ( `YCSB_KEY` String, `FIELD0` String, `FIELD1` String, `FIELD2` String, `FIELD3` String, `FIELD4` String, `FIELD5` String, `FIELD6` String, `FIELD7` String, `FIELD8` String, `FIELD9` String ) ENGINE=ROW_STORE PRIMARY KEY(`YCSB_KEY`); -- 单行查询 SELECT * FROM ads_table WHERE YCSB_KEY = 'abc'; -- 多行查询 SELECT * FROM ads_table WHERE YCSB_KEY in ('abc', 'def'); -- 小范围查询 SELECT * FROM ads_table WHERE YCSB_KEY > 'abc' AND YCSB_KEY < 'ac';
2 维表查询场景
维表一般适用于点查询场景,而列存表对于点查场景性能开销较大。因此建议采用行存表。
2.1 OLAP维表关联
-- 事实表采用列存表模式存储 CREATE TABLE factor_table ( `c1` String, `c2` String, `c3` String, `c4` String, `c5` String, `c6` String, `c7` String, `c8` String, `c9` String, `c10` String, `c11` String, `YCSB_KEY` String ) ENGINE=OLAP PRIMARY KEY(`c1`); -- 维表采用行存表模式 CREATE TABLE dim_table ( `YCSB_KEY` String, `FIELD0` String, `FIELD1` String, `FIELD2` String, `FIELD3` String, `FIELD4` String, `FIELD5` String, `FIELD6` String, `FIELD7` String, `FIELD8` String, `FIELD9` String ) ENGINE=ROW_STORE PRIMARY KEY(`YCSB_KEY`); -- 关联查询时, 维表存在主键过滤 SELECT c1, c4, FIELD0, FIELD7 FROM factor_table JOIN dim_table ON factor_table.YCSB_KEY = dim_table.YCSB_KEY WHERE factor_table.YCSB_KEY = 'axxxxx';
2.2 Flink维表关联
-- source表 CREATE TABLE source_table ( `YCSB_KEY1` String, `YCSB_KEY2` String, `FIELD0` String, `FIELD1` String, `FIELD2` String, `FIELD3` String, `FIELD4` String, `FIELD5` String, `FIELD6` String, `FIELD7` String, `FIELD8` String, `FIELD9` String, proctime as PROCTIME() ) WITH ( 'connector' = 'datagen', 'rows-per-second'='1' ); -- lookup_table为SR行存表, 主键为(YCSB_KEY1,YCSB_KEY2) CREATE TABLE lookup_table ( `YCSB_KEY1` String, `YCSB_KEY2` String, `FIELD0` String, `FIELD1` String, `FIELD2` String, `FIELD3` String, `FIELD4` String, `FIELD5` String, `FIELD6` String, `FIELD7` String, `FIELD8` String, `FIELD9` String ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://localhost:9030/db1', 'table-name' = 'lookup_table', 'username' = 'root', 'password' = '' ); -- flink LookUp查询, 主键必须全部关联 SELECT * FROM source_table JOIN lookup_table FOR SYSTEM_TIME AS OF datagen2_lookup.proctime ON source_table.YCSB_KEY1 = lookup_table.YCSB_KEY1 AND source_table.YCSB_KEY2 = lookup_table.YCSB_KEY2;
3 局部更新场景
在大数据建模的时候, 通过会通过ETL将原来的多表拉宽, 形成一张大宽表, 从而减少计算时候Join的个数, 提高性能.
然而在实时场景上, FlINK 执行多表Join的成本很高, 如果底层存储具备具有局部更新的能力, 就在存储完成Join, 这功能在FLINK也被称为Merge Join.
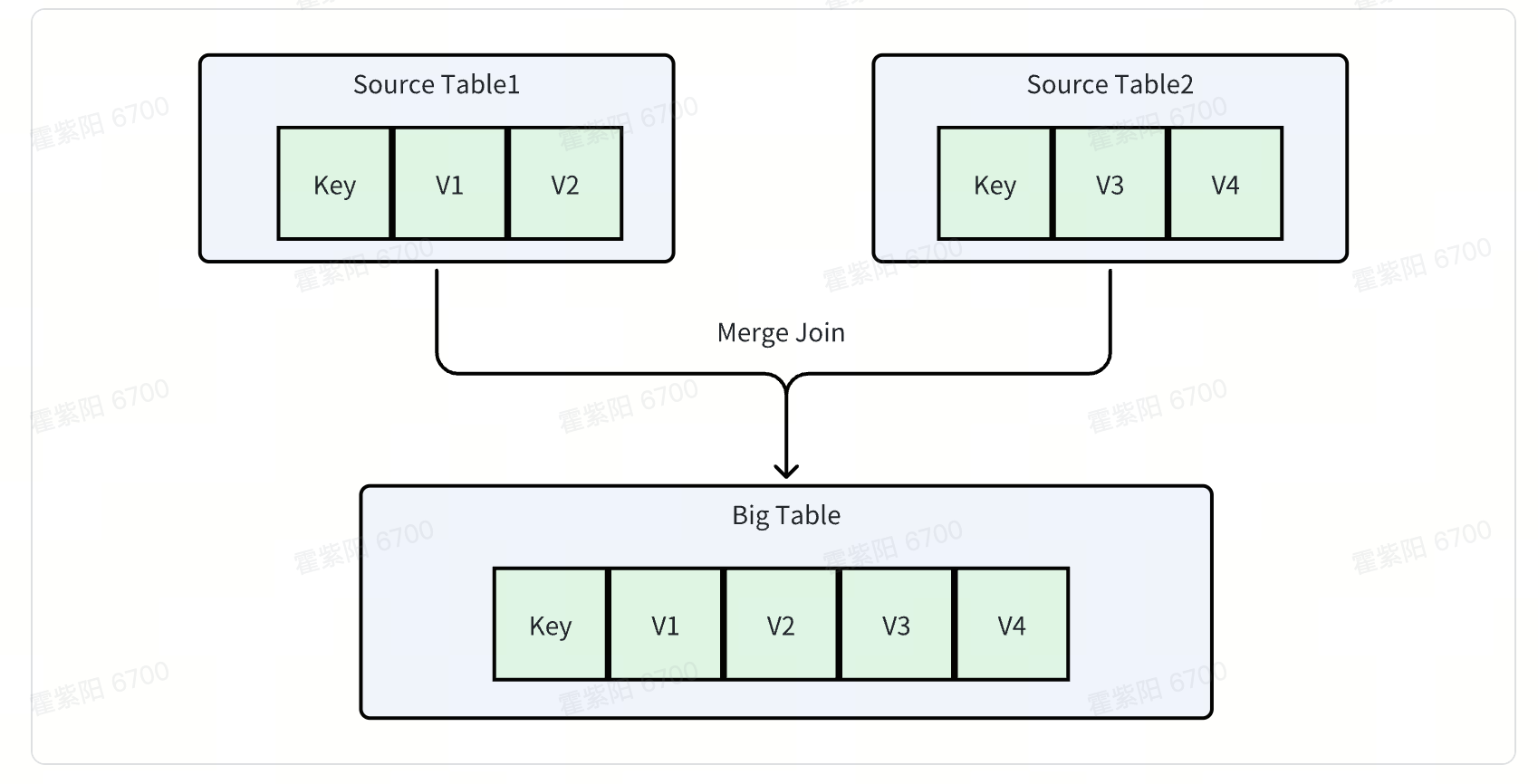
CREATE TABLE source_table1 ( `YCSB_KEY` String, `c1` String, `c2` String, `c3` String, `c4` String ) ENGINE=ROW_STORE PRIMARY KEY(`YCSB_KEY`); CREATE TABLE source_table2 ( `YCSB_KEY` String, `c5` String, `c6` String, `c7` String, `c8` String ) ENGINE=ROW_STORE PRIMARY KEY(`YCSB_KEY`); CREATE TABLE big_table ( `YCSB_KEY` String, `c1` String, `c2` String, `c3` String, `c4` String `c5` String, `c6` String, `c7` String, `c8` String ) ENGINE=ROW_STORE PRIMARY KEY(`YCSB_KEY`); -- upsert插入source_table1表数据 insert into big_table(YCSB_KEY,c1,c2,c3,c4) select YCSB_KEY,c1,c2,c3,c4 from source_table1 ON DUPLICATE KEY UPDATE c1 = source_table1.c1, c2 = source_table1.c2, c3 = source_table1.c3, c4 = source_table1.c4 -- upsert插入source_table2表数据 insert into big_table(YCSB_KEY,c5,c6,c7,c8) select YCSB_KEY,c5,c6,c7,c8 from source_table2 ON DUPLICATE KEY UPDATE c5 = source_table2.c5, c6 = source_table1.c6, c7 = source_table1.c7, c8 = source_table1.c8
SR局部更新的语法, 不仅支持upsert的能力, 同样也支持表达式计算
create table table4 ( `id` int(11) NOT NULL COMMENT "", `name` varchar(65533) NULL COMMENT "", `score` int(11) NOT NULL COMMENT "" ) ENGINE=ROW_STORE PRIMARY KEY(`id`); -- 常量赋值 INSERT INTO table4(id, name) VALUES (101, 'Lily'), (102, 'Rose'), (103, 'Alice') as v ON DUPLICATE KEY UPDATE name = 'ABC'; -- 表达式计算 INSERT INTO table4 VALUES (101, 'Lily', 70), (102, 'Rose', 80), (103, 'Alice', 90) as `values` ON DUPLICATE KEY UPDATE score = `values`.score + 1; -- 表达式计算并且引用表数据 INSERT INTO table4 VALUES (101, 'Lily', 70), (102, 'Rose', 80), (103, 'Alice', 90) as `values` ON DUPLICATE KEY UPDATE score = `table4`.score + 1;