集群资源规划是指在企业或组织中,通过合理配置和管理计算、存储、网络等资源,以提高系统的可靠性、可用性和效率,满足业务需求的过程。在进行集群资源规划时,需要考虑以下几个方面:
业务需求:根据业务的特点和需求,确定集群资源的规模和配置。
可用性:集群资源需要具有高可用性,以确保业务的连续性和稳定性。
性能:集群资源需要具有高性能,以满足业务的需求。
成本:集群资源的成本需要在企业或组织的预算范围内。
可扩展性:集群资源需要具有可扩展性,以满足业务的发展需求。
跟进写根据数据量和查询要求配置多少资源,多少fe,多少be
1 架构组件说明
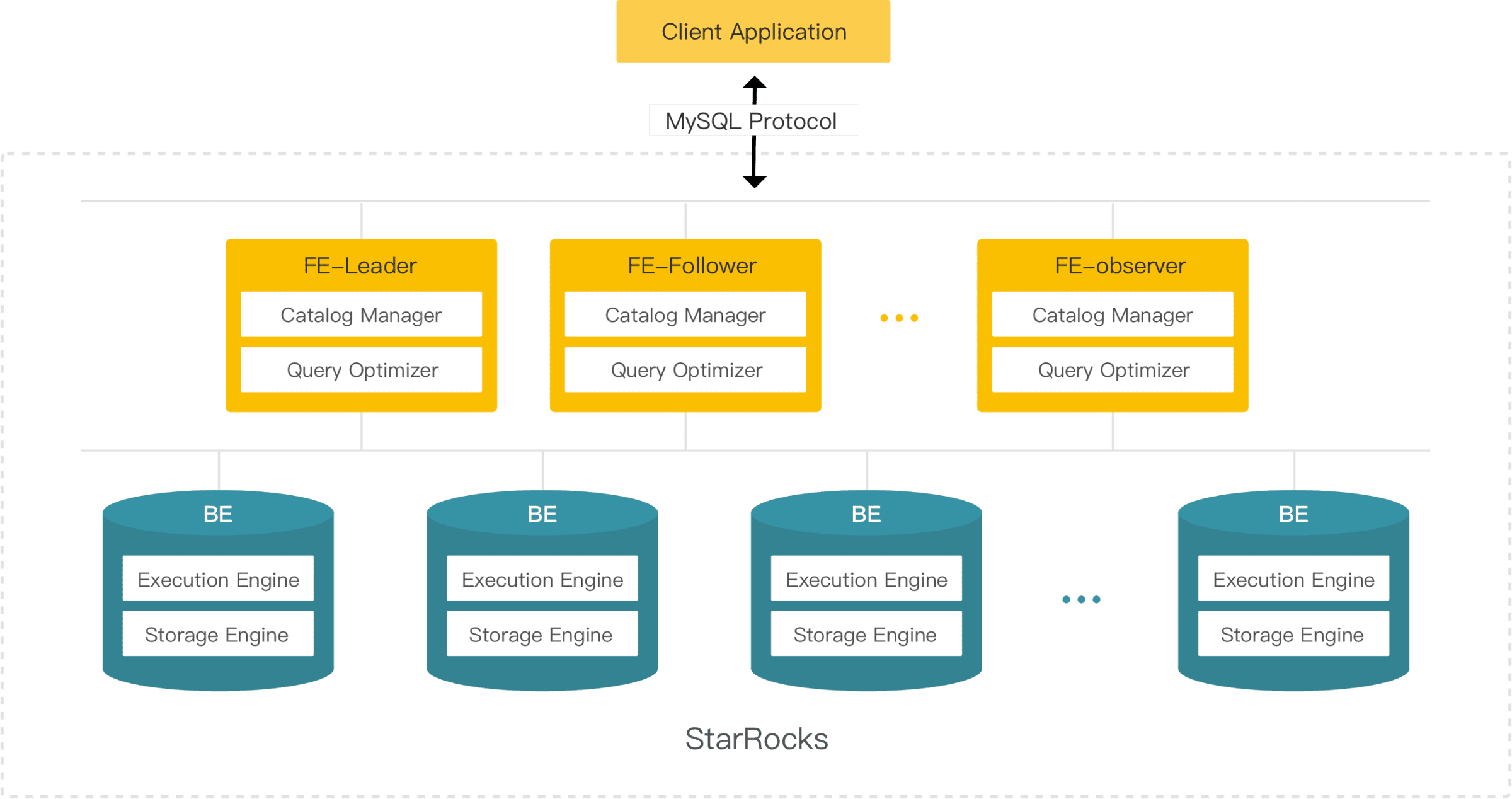
FE: StarRocks的前端接入节点,集群元数据存储在FE中的Catalog中,FE负责接收SQL,解析SQL,进行优化,并产生对应的执行计划,提交执行计划给BE,由BE负责任务的具体执行。
BE: StarRocks的后端执行节点,负责具体SQL任务执行,BE节点会在本地存储数据,也可以访问远端存储,例如HDFS/S3,获取对应表数据,进行计算。
2 节点数量
StarRocks 主要由两种类型的组件组成:FE 节点和 BE 节点。每个节点必须单独部署在物理机或虚拟机上。
2.1 FE 节点数量
FE 节点主要负责元数据管理、客户端连接管理、查询计划和查询调度。
对于 StarRocks 生产集群,建议您至少部署三个 Follower FE 节点,以防止单点故障。
StarRocks 通过 BDB JE 协议跨 FE 节点管理元数据。StarRocks 从所有 Follower FE 节点中选出一个 Leader FE 节点。只有 Leader FE 节点可以写入元数据,其他 Follower FE 节点只能根据 Leader FE 节点的日志更新元数据。如果 Leader FE 节点掉线,只要超过半数的 Follower FE 节点存活,StarRocks 就会重新选举出一个新的 Leader FE 节点。
如果您的应用程序会产生高并发查询请求,您可以在集群中添加 Observer FE 节点。Observer FE 节点只负责处理查询请求,不会参与 Leader FE 节点的选举。
2.2 BE 节点数量
BE 节点负责数据存储和 SQL 执行。
对于 StarRocks 生产集群,建议您至少部署三个 BE 节点,这些节点会自动形成一个 BE 高可用集群,避免由于发生单点故障而影响数据可靠性和服务可用性。
您可以通过增加 BE 节点的数量来实现查询的高并发。
2.3 CN 节点数量
CN 节点是 StarRocks 的可选组件,仅负责 SQL 执行。
您可以通过增加 CN 节点数量以弹性扩展计算资源,而无需改变集群中的数据分布。
3 CPU 和内存
通常,FE 服务不会消耗大量的 CPU 和内存资源。建议您为每个 FE 节点分配 8 个 CPU 内核和 16 GB RAM。
与 FE 服务不同,如果您的应用程序需要在大型数据集上处理高度并发或复杂的查询,BE 服务可能会使用大量 CPU 和内存资源。因此,建议您为每个 BE 节点分配 16 个 CPU 内核和 64 GB RAM。BE推荐16核64 GB以上。
3.1 基于数据量的资源评估基准
根据社区实践,一般情况下,1T的数据量qps不高的情况下,FE节点配置 8C-16G 200G*3,BE节点配置 16C-64G 800G*3,作为最小参考,还是需要根据实际业务场景测试下再估计的。
| 数据量 | FE节点CPU-Memory | BE节点CPU-Memory |
|---|---|---|
| 1TB | 8C - 16GB * 3 | 16C -64GB * 3 |
3.2 FE节点资源配置原则
FE是按节点算的,如果设定了高可用,就等于是三节点,每个节点都会占用相同的内存。文档只是设定了一个参考值,通常情况一千万个 Tablet的FE 内存使用在 20 GB左右除了元数据外,还需要考虑 SQL Session 的连接数对内存的占用,对SQL 处理过程对内存的占用。
当数据量翻倍时,或者其它情况qps上涨时,可以根据监控进行动态的调整。
3.3 BE 节点资源配置原则
BE 节点的总内存:
应该根据服务器的总物理内存来决定 BE 节点可用内存的上限。
留出足够的内存给操作系统和其他进程,通常建议至少保留 20%-30% 的系统内存给操作系统。
BE 节点配置:
BE 节点的相关内存配置在
be.conf(BE 配置文件)中设置。关键配置项包括
mem_limit和storage_page_cache_limit。mem_limit是 BE 进程可以使用的最大内存。storage_page_cache_limit负责表数据的页缓存。
数据量估计:
需要评估你的数据量大小以及预期增长,来设置足够的内存以适应数据量。
对于非常大的数据集,你可能需要更多的内存或者增加 BE 节点。
查询特性:
如果查询非常复杂,例如涉及大量的中间结果计算,或者需要高并发查询,内存的需求会更高。
对于同时需要处理大量写入操作的场景,也需要更多内存以保证查询性能。
监控与调优:
使用 StarRocks 提供的监控工具来分析BE节点的性能。
根据监控结果和系统日志来调整内存配置。
3.4 动态评估资源用量并规划
您可以通过以下方法查看分析 BE 内存使用。
- 通过浏览器或 curl 命令访问 Metrics 接口分析内存使用。
Metrics 统计每 10 秒更新一次。
curl -XGET -s http://be_ip:8040/metrics | grep "^starrocks_be_.*_mem_bytes\|^starrocks_be_tcmalloc_bytes_in_use"
说明
- 将以上
be_ip改为 BE 节点实际的 IP 地址。 - BE
be_http_port默认为8040。
- 通过浏览器或 curl 命令访问 mem_tracker 接口分析 BE 内存使用。
http://be_ip:8040/mem_tracker
说明
- 将以上
be_ip改为 BE 节点实际的 IP 地址。 - BE
be_http_port默认为8040。
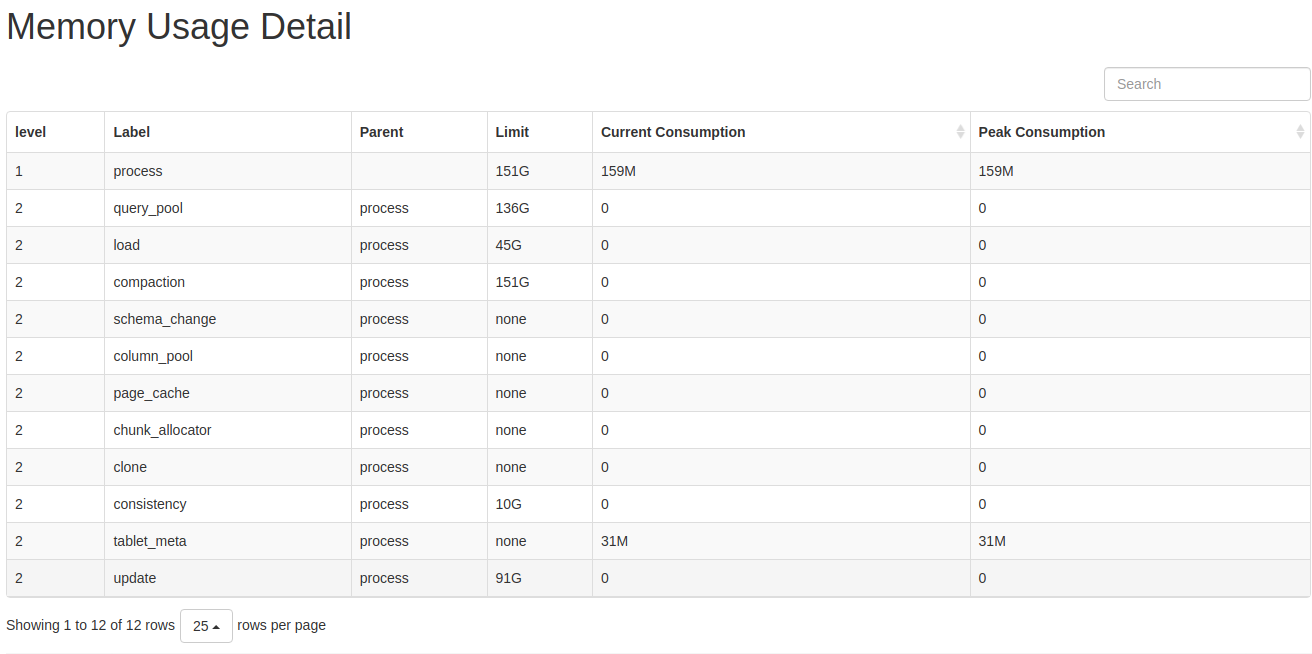
指标说明:
level: MemTracker 为树型结构,第一级为 BE 使用总内存,第二级为分类内存使用。Label: 标识内存分类Parent: 父结点 Label。Limit: 内存使用限制,-1表示没有限制。Current Consumption: 当前内存使用。Peak Consumption: 峰值内存使用。通过浏览器或 curl 命令访问 TCmalloc 接口分析 BE 内存使用。
http://be_ip:8040/memz
说明
- 将以上
be_ip改为 BE 节点实际的 IP 地址。 - BE
be_http_port默认为8040。
指标说明:
Bytes in use by application: BE 实际使用的内存。Bytes in page heap freelist: BE 已不再使用,但是尚未归还给操作系统的内存。Actual memory used: 操作系统监测到 BE 实际内存使用(BE 会预留一些空闲内存,不还给操作系统或是缓慢返还给操作系统)。Bytes released to OS: BE 已设置为可回收状态,但是操作系统尚未回收的内存。
3.4.1 详细内存分类
StarRocks BE 中的内存分为以下几类。
| 标识 | Metric 名称 | 说明 | BE 相关配置 |
|---|---|---|---|
| process | starrocks_be_process_mem_bytes | BE 进程实际使用的内存(不包含预留的空闲内存)。 | mem_limit |
| query_pool | starrocks_be_query_mem_bytes | BE 查询层使用总内存。 | |
| load | starrocks_be_load_mem_bytes | 导入使用的总内存。 | load_process_max_memory_limit_bytes, load_process_max_memory_limit_percent |
| table_meta | starrocks_be_tablet_meta_mem_bytes | 元数据总内存。 | |
| compaction | starrocks_be_compaction_mem_bytes | 版本合并总内存。 | compaction_max_memory_limit, compaction_max_memory_limit_percent |
| column_pool | starrocks_be_column_pool_mem_bytes | column pool 内存池,用于加速存储层数据读取的 Column Cache。 | |
| page_cache | starrocks_be_storage_page_cache_mem_bytes | BE 存储层 page 缓存。 | disable_storage_page_cache, storage_page_cache_limit |
| chunk_allocator | starrocks_be_chunk_allocator_mem_bytes | CPU per core 缓存,用于加速小块内存申请的 Cache。 | chunk_reserved_bytes_limit |
| consistency | starrocks_be_consistency_mem_bytes | 定期一致性校验使用的内存。 | consistency_max_memory_limit_percent, consistency_max_memory_limit |
| schema_change | starrocks_be_schema_change_mem_bytes | Schema Change 任务使用的总内存。 | memory_limitation_per_thread_for_schema_change |
| clone | starrocks_be_clone_mem_bytes | Tablet Clone 任务使用的总内存。 | |
| update | starrocks_be_update_mem_bytes | 主键表使用的总内存。 |
3.4.2 建议资源配置内存相关配置项
| 名称 | 默认值 | 说明 |
|---|---|---|
| mem_limit | 90% | BE 进程内存上限。可设为比例上限(如 "80%")或物理上限(如 "100G")。默认硬上限为 BE 所在机器内存的 90%,软上限为 BE 所在机器内存的 80%。如果 BE 为独立部署,则无需配置,如果 BE 与其它占用内存较多的服务混合部署,则需要合理配置。 |
| load_process_max_memory_limit_bytes | 107374182400 | 单节点上所有的导入线程占据的内存上限,取 mem_limit * load_process_max_memory_limit_percent / 100 和 load_process_max_memory_limit_bytes 中较小的值。如导入内存到达限制,则会触发刷盘和反压逻辑。 |
| load_process_max_memory_limit_percent | 30 | 单节点上所有的导入线程占据的内存上限比例,取 mem_limit * load_process_max_memory_limit_percent / 100 和 load_process_max_memory_limit_bytes 中较小的值,导入内存到达限制,会触发刷盘和反压逻辑。 |
| compaction_max_memory_limit | -1 | 所有 Compaction 线程的最大内存使用量,取 mem_limit * compaction_max_memory_limit_percent/100 和 compaction_max_memory_limit 中较小的值,-1 表示没有限制。当前不建议修改默认配置。Compaction 内存到达限制,会导致 Compaction 任务失败。 |
| compaction_max_memory_limit_percent | 100 | 所有 Compaction 线程的最大内存使用百分比,取 mem_limit * compaction_max_memory_limit_percent / 100 和 compaction_max_memory_limit 中较小的值,-1 表示没有限制。当前不建议修改默认配置。Compaction 内存到达限制,会导致 Compaction 任务失败。 |
| disable_storage_page_cache | FALSE | 是否开启 PageCache。开启 PageCache 后,StarRocks 会缓存最近扫描过的数据,对于查询重复性高的场景,会大幅提升查询效率。true 表示不开启。该配置项与 storage_page_cache_limit 配合使用,在内存资源充足和有大数据量 Scan 的场景中启用能够加速查询性能。自 2.4 版本起,该参数默认值由 TRUE 变更为 FALSE。 自 3.1 版本开始,该参数由静态变为动态。 |
| storage_page_cache_limit | 20% | BE 存储层 page 缓存可以使用的内存上限。 |
| chunk_reserved_bytes_limit | 2147483648 | 用于加速小块内存分配的 Cache,默认上限为 2GB。您可以在内存资源充足的情况下打开。 |
| consistency_max_memory_limit_percent | 20 | 一致性校验任务使用的内存上限,取 mem_limit * consistency_max_memory_limit_percent / 100 和 consistency_max_memory_limit 中较小的值。内存使用超限,会导致一致性校验任务失败。 |
| consistency_max_memory_limit | 10G | 一致性校验任务使用的内存上限,取 mem_limit * consistency_max_memory_limit_percent / 100 和 consistency_max_memory_limit 中较小的值。内存使用超限,会导致一致性校验任务失败。 |
| memory_limitation_per_thread_for_schema_change | 2 | 单个 Schema Change 任务的内存使用上限,内存使用超限,会导致 Schema Change 任务失败。 |
| max_compaction_concurrency | -1 | Compaction 线程数上限(即 BaseCompaction + CumulativeCompaction 的最大并发)。该参数防止 Compaction 占用过多内存。 -1 代表没有限制。0 表示不允许 compaction。 |
Session 变量
| 名称 | 默认值 | 说明 |
|---|---|---|
| query_mem_limit | 0 | 各 BE 节点上单个查询的内存限制,单位是 Byte。建议设置为 17179869184(16GB)以上。 |
| load_mem_limit | 0 | 各 BE 节点上单个导入任务的内存限制,单位是 Byte。如果设置为 0,StarRocks 采用 exec_mem_limit 作为内存限制。 |
4存储空间
4.1 FE 存储
由于 FE 节点仅在其存储中维护 StarRocks 的元数据,因此在大多数场景下,每个 FE 节点只需要 128 GB 的 HDD/SDD 存储。
4.2 BE 存储
4.2.1 预估 BE 初始存储空间
StarRocks 集群需要的总存储空间同时受到原始数据大小、数据副本数以及使用的数据压缩算法的压缩比的影响。
您可以通过以下公式估算所有 BE 节点所需的总存储空间:
BE 节点所需的总存储空间 = 原始数据大小 * 数据副本数/数据压缩算法压缩比 原始数据大小 = 单行数据大小 * 总数据行数
在 StarRocks 中,一个表中的数据首先被划分为多个分区(Partition),然后进一步被划分为多个 Tablet。Tablet 是 StarRocks 中基本数据管理逻辑单元。为保证数据的高可靠性,您可以为每个 Tablet 维护多个副本,存储于不同的 BE 节点。StarRocks 默认维护三个副本。
目前,StarRocks 支持四种数据压缩算法:zlib、Zstandard(或 zstd)、LZ4 和 Snappy(按压缩比从高至低排列)。这些数据压缩算法可以提供 3:1 到 5:1 的压缩比。
通过计算得到总存储空间后,你可以简单地将之除以集群中的 BE 节点数,估算出每个 BE 节点所需的平均存储空间。
4.2.2 随时添加额外存储空间
如果 BE 存储空间随着原始数据的增长而耗尽,您可以通过垂直或水平扩展集群或扩展云存储以补充存储空间。例如,我们可以在集群运行的时候,查看实际的存储大小,进行预估。
估算表的大小,分析 bucket 数量是否合理。一般一个 bucket 大小为 100MB 至 1GB(数据压缩后大小)。
登录 BE 实例的 ECS 节点上,查看数据存储目录(默认是
/data01/ju/output/be/storage/data) 下 Segment 文件增长速度:
find /data01/starrocks/be/storage/data -name *.dat |wc -l shell
示例:从数据开始导入,经过两个小时的导入文件数高达20万。导入频率较大,可以增加导入数据的大小
根据任务执行过程中分析 BE 的内存消耗,我们同样可以分析出是否需要进行内存扩容。
您可以在 StarRocks 集群中添加新的 BE 节点,从而将数据重新平分至更多节点上。添加新的 BE 节点后,StarRocks 会自动重新平衡数据在所有 BE 节点之间的分布。所有表类型均支持这种自动平衡。在 BE 节点上添加额外的存储卷。添加额外的存储卷后,StarRocks 会自动重新平衡所有表中的数据。
4.2.3 基于存算分离的弹性BE存储空间
StarRocks 存算分离集群采用了存储计算分离架构,特别为云存储设计。在存算分离的模式下,StarRocks 将数据存储在兼容 S3 协议的对象存储TOS中,而本地盘作为热数据缓存,用以加速查询。通过存储计算分离架构,您可以降低存储成本并且优化资源隔离。除此之外,集群的弹性扩展能力也得以加强。在查询命中缓存的情况下,存算分离集群的查询性能与存算一体集群性能一致。
相对存算一体架构,StarRocks 的存储计算分离架构提供以下优势:
廉价且可无缝扩展的存储。
弹性可扩展的计算能力。由于数据不存储在 CN 节点中,因此集群无需进行跨节点数据迁移或 Shuffle 即可完成扩缩容。
热数据的本地磁盘缓存,用以提高查询性能。
可选异步导入数据至对象存储,提高导入效率。