E-MapReduce
- 文档首页 /E-MapReduce/组件操作指南/ClickHouse/概述
Clickhouse 是一个分布式实时分析型列式数据库产品,它能够亚秒级响应时间即可获得查询结果,可高效地进行实时数据分析。在用户行为分析、流量和监控、用户画像、实时BI报表等业务场景有广泛的应用。
1 Clickhouse 功能特点
| 功能特点 | 说明 |
|---|---|
| 列式存储 | Clickhouse 无论在内存还是磁盘都是使用列存格式存储数据,相较于行式存储,列式存储在分析型查询上性能上更优。同时列式存储的数据压缩比更高,更加节省存储空间。 |
| 向量化执行 | Clickhouse 使用向量化执行模型,所有操作算子都按照向量化模式开发,能够使用 CPU 的 SIMD 指令集,从而更高效的使用 CPU。 |
多种表引擎 | Clickhouse 拥有多种表引擎,支持多种的 MergeTree 表引擎,例如 ReplicatedMergeTree 支持多副本高可用的 MergeTree,AggregatingMergeTree 支持数据预聚合的 MergeTree,还有 ReplacingMergeTree 支持数据实时更新/实时去重的 MergeTree。 |
物化视图 | Clickhouse 支持实时物化视图功能,创建物化视图后,当底表数据有新的插入后,物化视图也能够进行实时数据更新。 |
多种接入方式 | Clickhouse 支持多种接入方式, 通常我们使用 Clickhouse-Client 进行查询操作, 也可以通过 JDBC 进行远程连接。 |
| 多种索引 | Clickhouse 支持主键索引和二级索引,Clickhouse 的数据存储时,会按照主键排序,然后在主键上,创建 minmax 索引,因此 ClickHouse 可以在几十毫秒以内完成对数据特定值或范围的查找。 二级索引类型更加多样,支持 minmax/set/ngrambf_v1/tokenbf_v1/bloom_filter。 |
2 架构说明
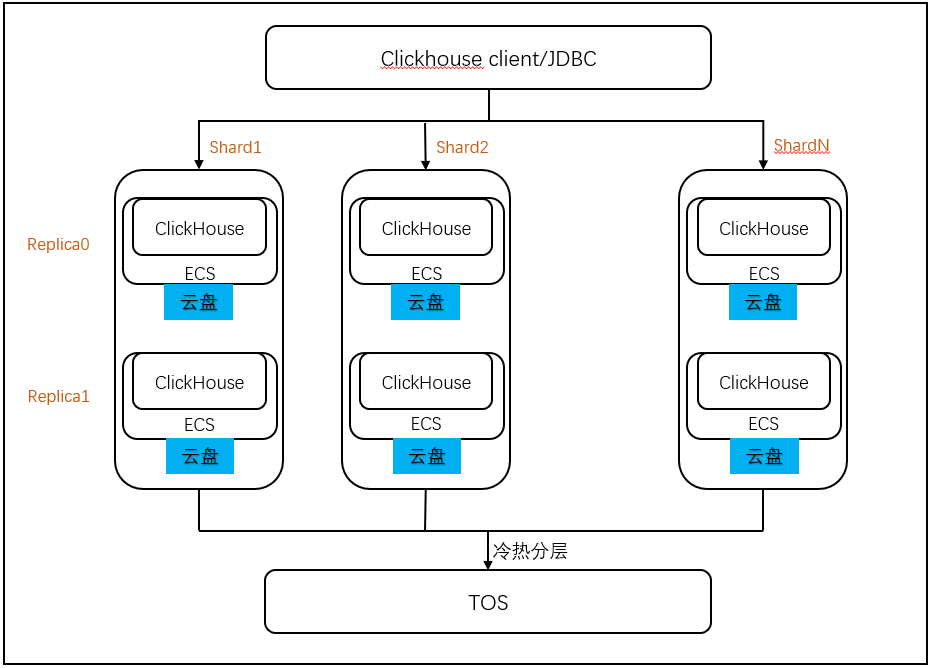
如上图所示, 该 ClickHouse 集群总共有 2*N 个 Clickhouse 节点,两两互为副本,共分为 N 个 Shard,N 个 Shard 的含义:表示数据会按照 Shard Key 的函数值分为 N 份,数据将相对均衡的分布在这 N 个 Shard 中。
在同一个 Shard 中,数据同时存储在 Replica0 和 Replica1 中,新插入的数据只写入到其中一个 Replica 中,Clickhouse 引擎会自动将数据同步到另外一个 Replica 中。
Clickhouse 支持数据冷热分层,热数据可以存放在 ECS 的本地云盘上,这类数据的查询性能更快,冷数据存储在远程的对象存储 TOS 中,这类数据的存储成本更低。
Clickhouse 支持 Client 和 JDBC 接入,您可以选择多节点模式接入,或者将这些节点绑定到 ELB 上,通过连接 ELB 访问。
更多信息可以参考Clickhouse官网。