Spark是专为大规模数据分析处理而设计的开源分布式计算框架。使用内存计算技术和有向无环图(DAG)提供比MapReduce引擎更快的分析处理能力。提供Spark SQL、Spark Streaming、MLlib和Graphx等多个计算程序包,可用于大规模数据分析处理,实时计算,机器学习,图计算等场景。
EMR Spark在完全兼容开源Spark的基础上,做了定制和优化,提供了如下能力:
1 UIService:云原生 Spark History Server
原生的 Spark History Service 存在以下问题:
- 存储空间开销大
Spark 的事件体系非常详细,导致 event log 记录的事件数量非常大,对于 UI 显示来说,大部分 event 是无用的。并且 event log 一般使用 Json 明文存储,空间占用较大。
- 回放效率差,延迟高
History Server 采用回放解析 event log 的方式还原 Spark UI,有大量的计算开销,当任务较大就会有明显的响应延迟,大型作业结束之后,用户可能要等十几分钟甚至半小时才能通过 History Server 看到作业历史,非常影响用户体验。
- 扩展性差
History Server 的 FsHistoryProvider 在回放解析文件之前,需要先扫描配置的 event log 路径,遍历其中的 event log,将所有文件的元信息加载到内存中,这使得原生服务成为了有状态的服务。因此每次服务重启,都需要重新加载整个路径,才能对外服务。每个任务在完成后,也需要等待下一轮扫描才能被访问到。难以方便的进行水平扩展。
- 非云原生
Spark History Server 并非是云原生的服务,不同租户的 workload 差异很大,在公有云场景下改造和维护成本高。
为了解决前面的几个问题,我们尝试对 History Server 进行改造。
无论运行中 Spark Driver 还是 History Server,都是通过监听 event,将其中包含的任务变化信息反映到几种 UI 相关的类的实例中,然后存入 KVStore 供 UI 渲染。也就是说,KVStore 中存储着 UI 显示所需的完备信息。对于 History Server 的用户来说,绝大多数情况下我们只关心任务的最终状态,而无需关心引起状态变化的具体 event。因此,我们可以只将 KVStore 持久化下来,而不需要存储大量冗余的 event 信息。此外,KVStore 原生支持了 Kryo 序列化,性能明显于 Json 序列化。我们基于此思想重写了一套新的 History Serve 系统,命名为 UIService。
通过构建 UIService,我们极大的节省了 Spark UI 相关 event 的存储空间,并有效的提升了 UI 访问延迟性能,在架构上我们也基于 UIService 实现了多租户访问隔离,云原生和弹性伸缩能力。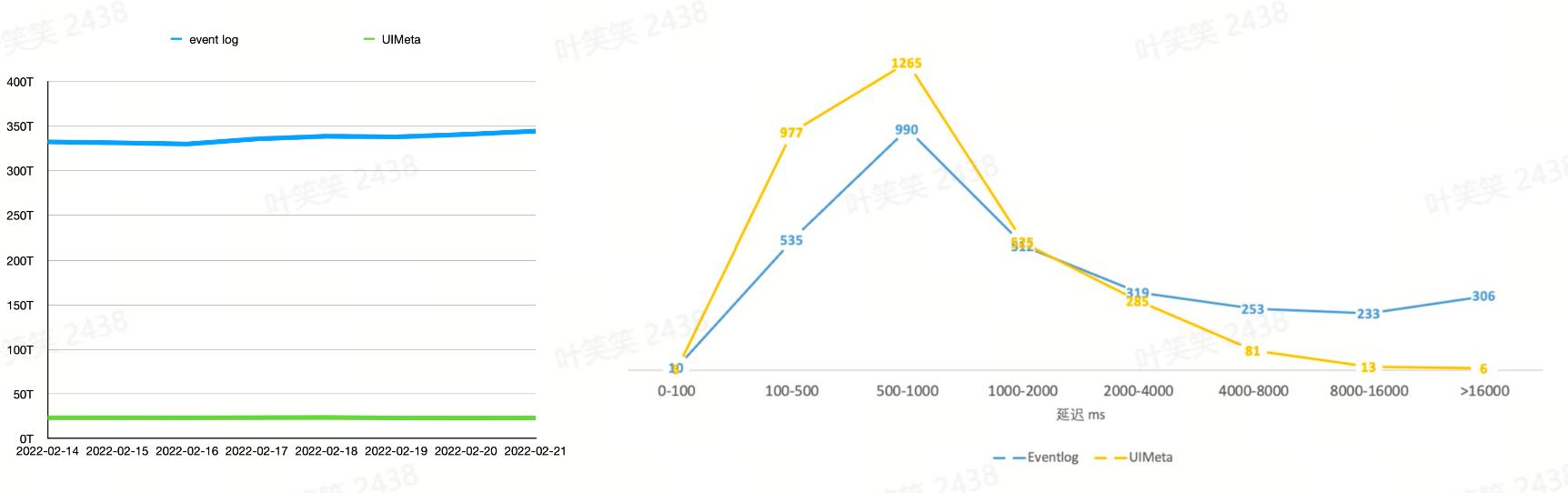
2 Falcon:Remote Shuffle Service
除了 UIService 之外,Shuffle 层面的优化也是一个值得重点分享的课题。Shuffle 是 Spark 作业中用于连接上下游数据交互的过程。Remote Shuffle Service(RSS)框架允许 Shuffle Service 在 Spark 之外运行,解耦了存储和计算,提供更好的可用性和性能。
Falcon 是 EMR Serverless Spark 上的 Remote Shuffle Service,采用高可用及存算分离的架构。它能够支持 Spark 引擎进行远程 Shuffle 数据的读取和写入,并可在云环境中部署和应用。详情可参考:数据Shuffle
3 Bolt:Spark Native Engine
Bolt是字节自研的的数据处理和分析加速引擎。它解决了大数据处理和分析领域中存在的性能问题,提供更快速、更可靠、更灵活易用的分析加速。 Bolt 使用C++实现的向量化执行引擎、结合运行时LLVM Codegen代码生成技术,大幅提升了多核CPU的并行执行性能效率。在分布式SQL查询引擎Spark上,替换掉传统的Java引擎,可以大幅提升查询速度、降低资源成本。
Spark on Bolt使用Gluten plugin作为框架与native引擎的粘合层。 主要包含几部分:Conversion 组件,把 Spark Physical Plan转成 Substrait Plan。Memory Manager,Bolt是脱离 JVM 的,需要把Bolt 的内存交给 Spark 统一来管理,避免内存溢出,Bolt会将申请的内存报告给Task Memory Manager,当Executor内存不足时,Spark会触发Bolt Spill逻辑来释放内存或将部分内存写入磁盘。Columnar Shuffle,Spark 原生的 Shuffle 是基于 Row 的,需要扩展支持列式Shuffle,去做列式数据split、序列化、压缩,会通过延迟分配、采样预测等方式减少列式Shuffle过程中的内存占用。Fallback 组件,Spark支持的算子表达式很多,当遇到 Bolt 不支持的情况时fallback 到原生 JVM 引擎去执行,有统一函数签名注册机制来减少标量、聚合函数的实现成本,不同框架依赖的函数可复用和override。数据传递,JVM与Bolt之间,通过JNI调用实现数据传递,Bolt返回的数据存储为 Block Columnar Vector,方便后续的计算。
更多介绍和使用可参考:Spark on Bolt使用说明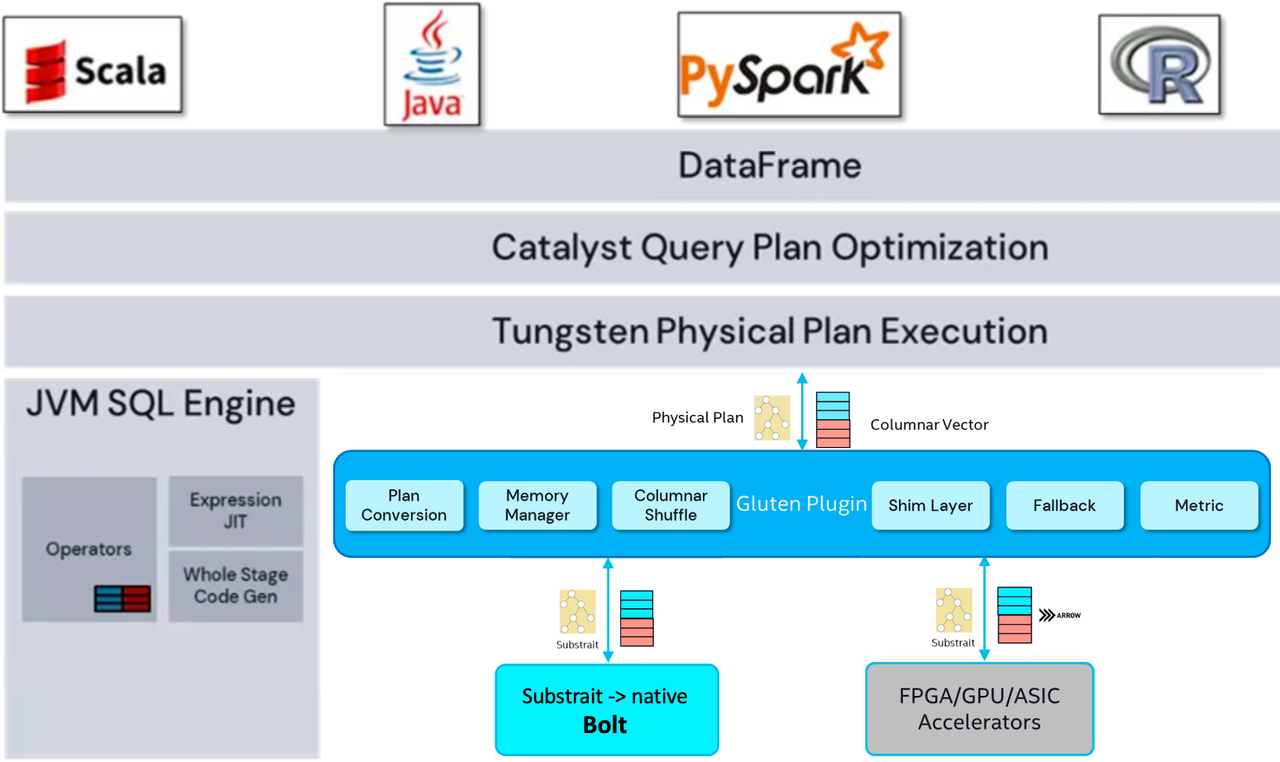
4 TPC-DS 优化
TPC-DS 测试集作为 TPC 组织推出的一个基于决策支持系统的测试基准,模拟了一个复杂的数据仓库环境,覆盖了多种业务领域,能够有效地测试和评估 OLAP 引擎在处理不同业务场景下的性能和效率,使得不同 OLAP 引擎之间的性能比较更加公平和可靠。
EMR Serverless Spark 相比社区有较大的性能提升,这些性能提升一部分来源于字节内部已有的性能优化,例如AdaptiveShuffledHashJoin、AdaptiveFileSplit 等;还有一部分来源于对 TPC-DS 数据集的研究和挖掘。在对 TPC-DS 的 workload 的测试和研究中,我们分别针对性地在引擎层面上做了规则优化、缓存优化和运行时优化。
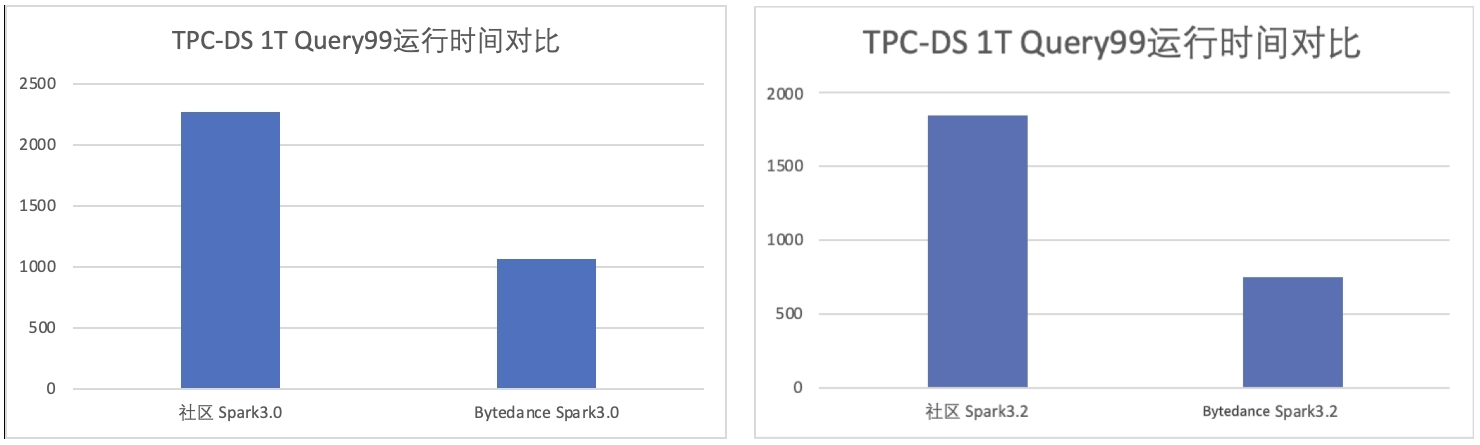
优化后相比于社区版本在 TPC-DS 1T 数据集上的性能对比,在相同的硬件资源下, 3.0 版本达到了社区 3.0 版本性能的 2.1x,3.2 版本达到了社区 3.2 版本性能的 2.5x。