背景
ByteHouse 是火山引擎旗下基于开源 ClickHouse 的企业级分析型数据库,是一个同时支持实时和离线导入的自助数据分析平台,能够对 PB 级海量数据进行高效分析。
本文将介绍如何在 E-MapReduce(EMR) 集群提交 Flink SQL 和 Flink jar 任务,将数据写入到 ByteHouse 集群的方法。
EMR Flink 数据写入ByteHouse(云数仓版)
前提条件
- 已创建火山引擎 EMR 集群。具体操作,请参见 创建集群。
- 已创建火山引擎 ByteHouse 集群。具体操作,请参见 ByteHouse 快速入门-火山引擎。
准备工作
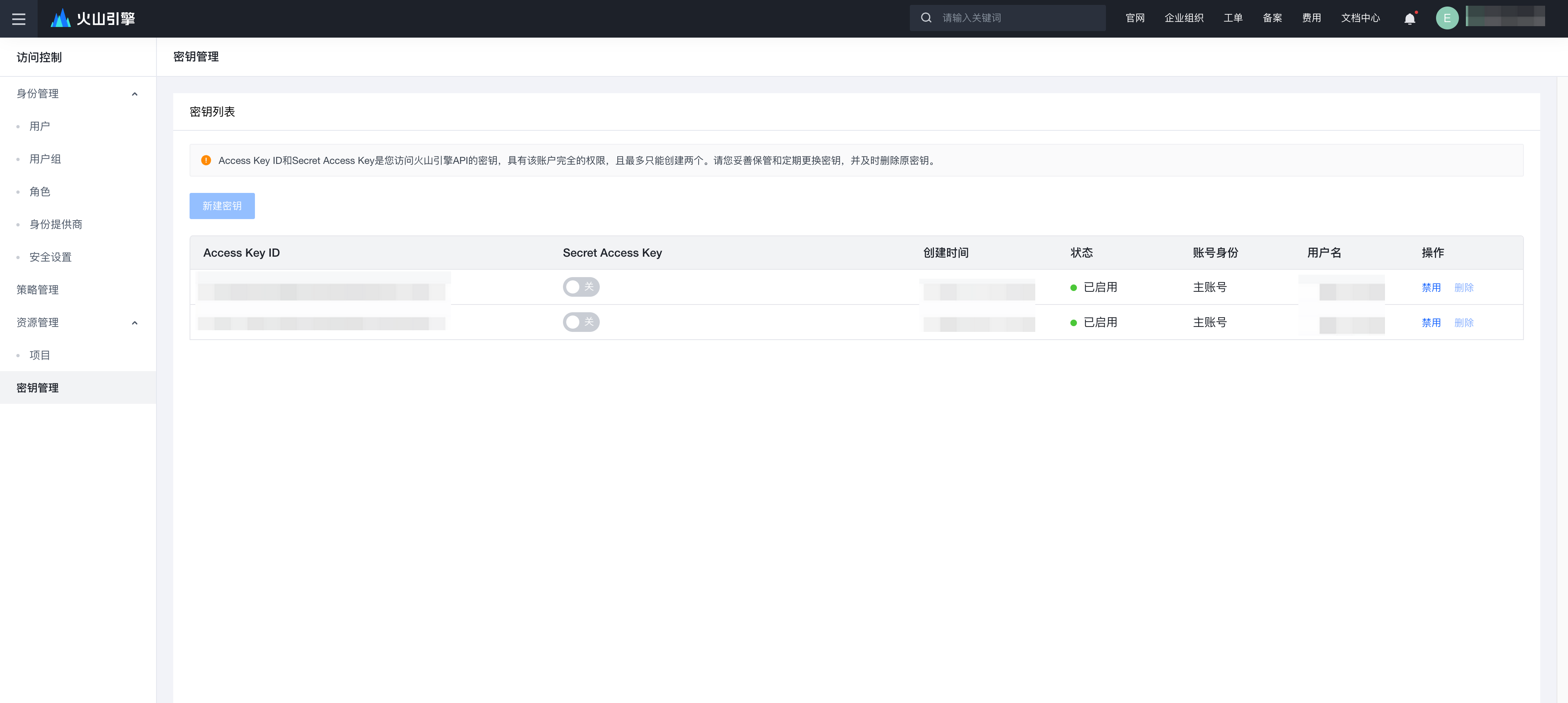
- 生成访问密钥,在火山引擎的 密钥管理 页面,查找对应用户的访问秘钥(Access Key ID 和 Secret Access Key)
- 向 ByteHouse 写数据,是通过 ByteHouse Gateway 实现的。具体方式为在使用过程中将参数
Region,根据使用场景设置为不同的值 。同时需要 EMR 集群的各个节点能够与之进行通信,当前有以下两种方式:- 设置
Region为VOLCANO,给 EMR 集群的每个节点绑定一个公网 IP; - ByteHouse Gateway 也支持火山引擎内网访问方式,需要 ByteHouse 侧给 EMR 集群加白,可 联系客服 进行操作。
- 设置
Flink SQL 集群执行
运行 Flink SQL client 时根据如下路径指定 jar。
cd /usr/lib/emr/current ./bin/sql-client.sh --jar connectors/flink-connector-bytehouse-cdw-assembly-x.x.x-x.x.jar
可运行如下 SQL,进行测试运行。
CREATE TABLE random_source ( test_key STRING, test_value BIGINT, ts BIGINT ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '1' ); CREATE TABLE cnch_table (test_key STRING, test_value BIGINT, ts BIGINT) WITH ( 'connector' = 'bytehouse-cdw', 'database' = '<此处填写 ByteHouse 库名>', 'table-name' = '<此处填写 ByteHouse 表名>', 'bytehouse.gateway.region' = 'VOLCANO', 'bytehouse.gateway.access-key-id' = '<此处填写用户实际的 AK>', 'bytehouse.gateway.secret-key' = '<此处填写用户实际的 SK>' ); INSERT INTO cnch_table SELECT * FROM random_source;
Flink JAR 包作业集群提交
下载对应版本的 Connector
访问 ByteHouse Connector 下载地址,选择对应版本目录下的文件进行下载。
下载后的文件命名格式为:flink-connector-bytehouse-cdw-assembly-#.#.#-#.#.jar。
注意
EMR 1.4.0 集群中集成了 Flink 1.15;EMR 1.3.1 集群中集成了 Flink 1.11。
导入依赖
在本地 Maven 项目的 pom.xml 文件中添加以下配置以导入对应依赖,其中 flink-cnch-connector 中安装至本地 maven 仓库。
mvn install:install-file -Dfile=/xxx/xxx/flink-connector-bytehouse-cdw-assembly-1.11.4-1.15.jar -DgroupId=com.bytedance -DartifactId=flink-cnch-connector -Dversion=1.0.0 -Dpackaging=jar
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>flinkTest</artifactId> <version>1.0-SNAPSHOT</version> <properties> <java.version>1.8</java.version> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <flink.version>1.11.3</flink.version> <scala.version>2.11</scala.version> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-core</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>com.bytedance</groupId> <artifactId>flink-cnch-connector</artifactId> <version>1.0</version> </dependencies> </project>
DummyRowData.java 源数据生成样例
/** * Synthetic {@code RowData} generator mimicking the feed of crime cases reported by Neighbourhood * Police Centres (NPCs) in Singapore. */ public class DummyRowDataSource extends RichParallelSourceFunction<RowData> { private static final AtomicLong pullCount = new AtomicLong(); static Map<String, Timer> map = new ConcurrentHashMap<>(2, 0.9f, 1); private final List<String> offences = Arrays.asList("Unlicensed Moneylending", "Harassment"); private final AtomicInteger caseNo = new AtomicInteger(); private volatile boolean cancelled = false; private Random random; @Override public void open(Configuration parameters) throws Exception { super.open(parameters); random = new Random(); map.computeIfAbsent( "holder", s -> { final Timer timer = new Timer("RandomStringSource ", true); timer.schedule( new TimerTask() { @Override public void run() { System.out.printf("source is pulled %s times\n", pullCount.get()); } }, 5000, 5000); return timer; }); } @Override public void run(SourceContext<RowData> ctx) throws Exception { while (!cancelled) { Thread.sleep(random.nextInt(10) + 5); synchronized (ctx.getCheckpointLock()) { final GenericRowData genericRowData = new GenericRowData(RowKind.INSERT, 4); genericRowData.setField(0, RowDataConversion.fieldDataOf(2000 + random.nextInt(20))); genericRowData.setField(1, RowDataConversion.fieldDataOf(generateRandomWord(4))); genericRowData.setField(2, RowDataConversion.fieldDataOf(randomOffences())); genericRowData.setField(3, RowDataConversion.fieldDataOf(caseNo.incrementAndGet())); ctx.collect(genericRowData); pullCount.incrementAndGet(); } } } @Override public void cancel() { cancelled = true; } private String generateRandomWord(int wordLength) { StringBuilder sb = new StringBuilder(wordLength); for (int i = 0; i < wordLength; i++) { // For each letter in the word char tmp = (char) ('a' + random.nextInt('z' - 'a')); // Generate a letter between a and z sb.append(tmp); // Add it to the String } return sb.toString(); } private String randomOffences() { return offences.get(random.nextInt(2)); } }
CnchSinkDataStreamExample.java 数据 sink 样例
根据提示,填写用户实际的 AK,SK,ByteHouse 的库名及表名。
public class CnchSinkDataStreamExample { public static void main(String[] args) throws Exception { final String region = "VOLCANO"; final String ak = "<此处填写用户实际的 AK>"; final String sk = "<此处填写用户实际的 SK>"; final String dbName = "<此处填写 ByteHouse 库名>"; final String tableName = "<此处填写 ByteHouse 表名>"; // create env final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // add source DataStream<RowData> dataStream = env.addSource(new DummyRowDataSource()).returns(TypeInformation.of(RowData.class)); List<TableColumn> columns = Arrays.asList( TableColumn.of("year", DataTypes.INT()), TableColumn.of("npc", DataTypes.STRING()), TableColumn.of("offence", DataTypes.STRING()), TableColumn.of("case_no", DataTypes.INT())); try (AbstractClickHouseSinkFunction<RowData, InsertBatch<RowData>, ?> cnchSink = new CnchSinkFunctionBuilder(dbName, tableName) .withSchema(columns) .withGatewayConnection(region) .withGatewayCredentials(ak, sk) .withFlushInterval(Duration.ofSeconds(1)) .build()) { // add sink dataStream.addSink(cnchSink); // trigger pipeline env.execute(CnchSinkDataStreamExample.class.getSimpleName()); } } }
编译项目生成可运行 jar
为了减少潜在的包冲突文件,建议用户打 fat jar,集成相关依赖。
在项目 pom.xml 文件中,添加如下 build 方式,以生成 fat jar。
<build> <finalName>fat-jar-example</finalName> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.4.2</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>assemble-all</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
上传 jar 包到 EMR 集群
可通过 scp 指令。
scp xxxx.jar root@xxx.xxx.xxx.xxx:/{path}/
执行任务
提交任务的命令:
/usr/lib/emr/current/flink/bin/flink run-application -t yarn-application <JAR 包文件名>
注意
- 可以以 flink 用户身份运行
- 运行前执行
export HADOOP_CONF_DIR=/etc/emr/hadoop/conf
Yarn ResourceManager UI 查看运行状态

Yarn ResourceManager UI 访问方式,可参考访问链接 E-MapReduce-火山引擎。
EMR Flink 数据写入ByteHouse(企业版)
前提条件
- 已创建火山引擎 EMR 集群(集群版本需高于3.8.0)。具体操作,请参见创建集群。
- 已创建火山引擎ByteHouse(企业版),具体操作,请参见ByteHouse企业版快速入门-火山引擎。
准备工作
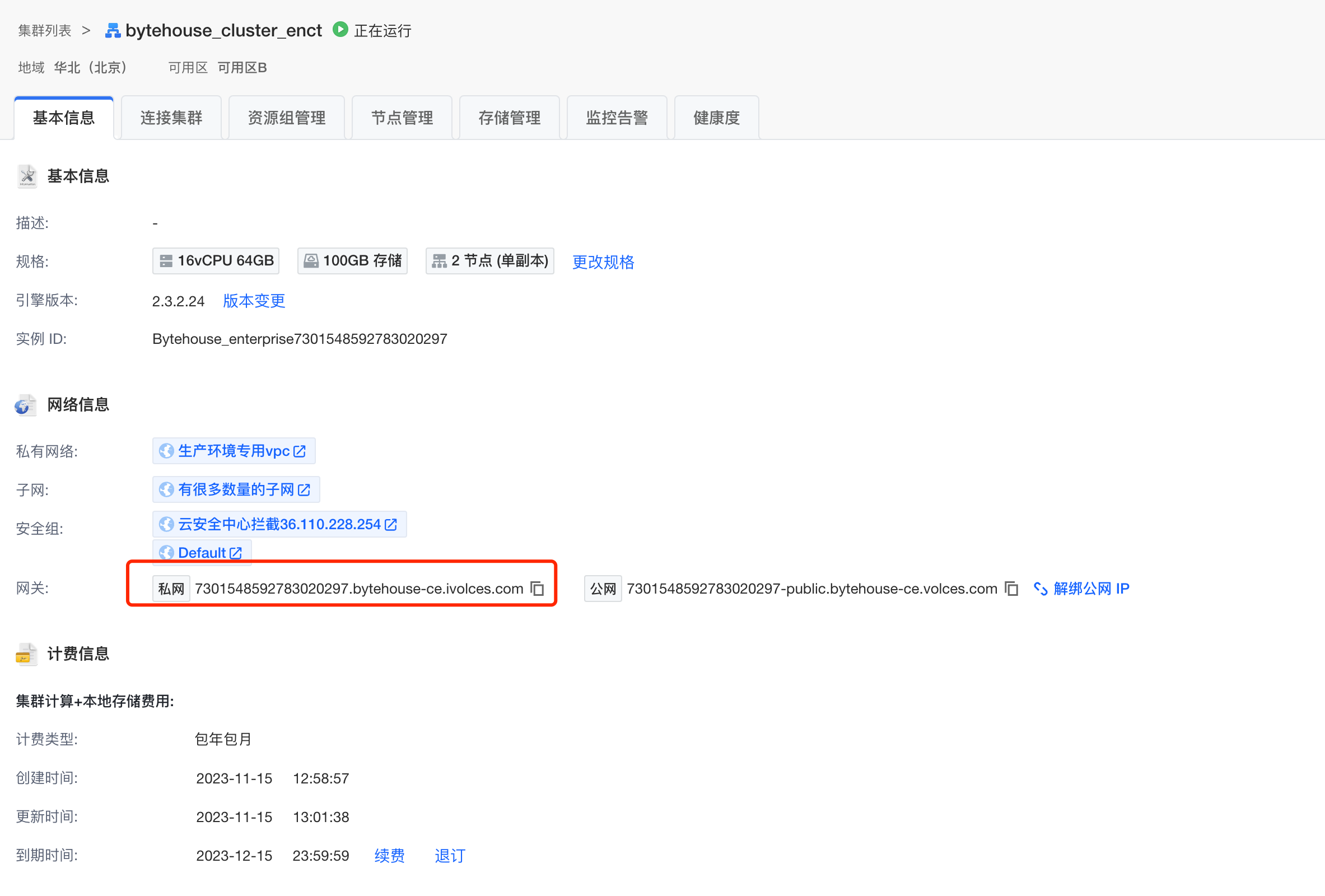
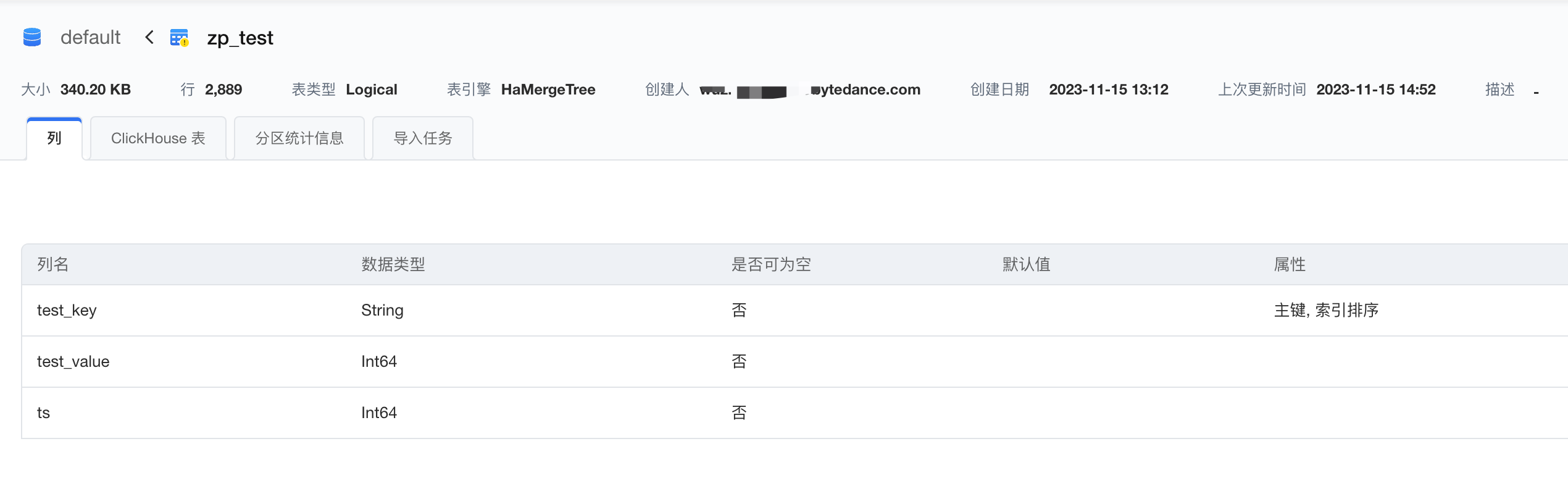
在创建的ByteHouse 企业版集群建表
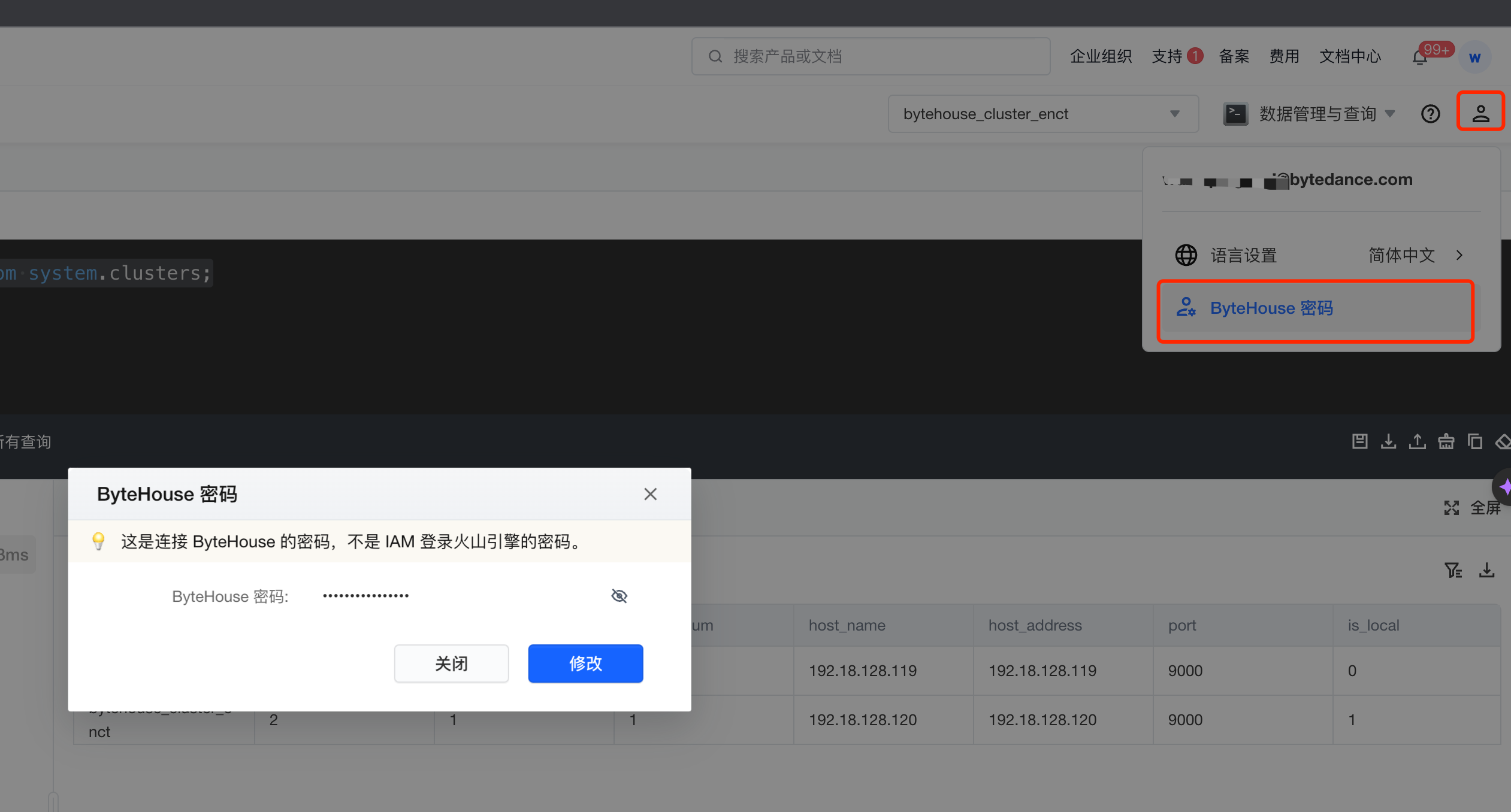
获取用户认证信息
Flink SQL 集群执行
运行Flink SQL client时根据如下路径指定jar。
cd /usr/lib/emr/current ./bin/sql-client.sh --jar connectors/[flink-sql-connector-bytehouse-ce](https://maven.byted.org/repository/releases/com/bytedance/bytehouse/flink-sql-connector-bytehouse-ce_2.12/1.25.4-1.16/flink-sql-connector-bytehouse-ce_2.12-1.25.4-1.16.jar)-x.x.x-x.x.jar
可运行如下SQL,进行测试运行。
CREATE TABLE random_source ( test_key STRING, test_value BIGINT, ts BIGINT ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '1' ); CREATE TABLE cnch_table (test_key STRING, test_value BIGINT, ts BIGINT) WITH ( 'connector' = 'bytehouse-ce', 'clickhouse.shard-discovery.kind' = 'CE_GATEWAY', 'bytehouse.ce.gateway.host' = '7301548592783020297.bytehouse-ce.ivolces.com', 'bytehouse.ce.gateway.port' = '8123', 'sink.enable-upsert' = 'false', 'clickhouse.cluster' = 'bytehouse_cluster_enct', -- bytehouse集群名称 'database' = 'default', -- 目标数据库 'table-name' = 'zp_test', -- 目标表 注意是local表:{table_name}_local 'username' = 'xxxx@bytedance.com', -- 2.3步获取的用户名 'password' = 'xxx' -- 2.3步获取的bytehouse密码 ); INSERT INTO cnch_table SELECT * FROM random_source;
Flink JAR 包作业集群提交
下载 Flink ByteHouse CE 的connector


注意
EMR 1.8.0 集成1.16。
导入依赖
在本地 Maven 项目的 pom.xml 文件中添加以下配置以导入对应依赖,其中 flink-sql-connector-bytehouse-ce 中安装至本地maven仓库。
在本地 Maven 项目的 pom.xml 文件中添加以下配置以导入对应依赖,其中 flink-sql-connector-bytehouse-ce 中安装至本地maven仓库 mvn install:install-file -Dfile=/xxx/xxx/flink-sql-connector-bytehouse-ce_2.12-1.25.4-1.16.jar -DgroupId=com.bytedance.bytehouse -DartifactId=flink-sql-connector-bytehouse-ce_2.12 -Dversion=1.25.4-1.16 -Dpackaging=jar
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>example.flink</groupId> <artifactId>bytehouse-ce</artifactId> <version>0.0.1-SNAPSHOT</version> <dependencies> <dependency> <groupId>com.bytedance.bytehouse</groupId> <artifactId>flink-sql-connector-bytehouse-ce_2.12</artifactId> <version>1.25.4-1.16</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner_2.12</artifactId> <version>1.16.2</version> <scope>provided</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>8</source> <target>8</target> </configuration> </plugin> </plugins> </build> </project>
DummyRowDataSource.java 源数据生成样例
package com.bytedance.bytehouse.ce.examples; import com.bytedance.bytehouse.flink.table.api.RowDataConstructor; // CHECKSTYLE:OFF: checkstyle:AvoidStarImport import java.util.*; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.atomic.AtomicInteger; import java.util.concurrent.atomic.AtomicLong; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction; import org.apache.flink.table.api.DataTypes; import org.apache.flink.table.data.RowData; import org.apache.flink.table.types.DataType; /** * Synthetic {@code RowData} generator mimicking the feed of crime cases reported by Neighbourhood * Police Centres (NPCs) in Singapore. */ public class DummyRowDataSource extends RichParallelSourceFunction<RowData> { private static final AtomicLong pullCount = new AtomicLong(); static Map<String, Timer> map = new ConcurrentHashMap<>(2, 0.9f, 1); private final List<String> offences = Arrays.asList("Unlicensed Moneylending", "Harassment"); private final AtomicInteger caseNo = new AtomicInteger(); private volatile boolean cancelled = false; private Random random; @Override public void open(Configuration parameters) throws Exception { super.open(parameters); random = new Random(); map.computeIfAbsent( "holder", s -> { final Timer timer = new Timer("RandomStringSource ", true); timer.schedule( new TimerTask() { @Override public void run() { System.out.printf("source is pulled %s times\n", pullCount.get()); } }, 5000, 5000); return timer; }); } private final RowDataConstructor rowDataConstructor = RowDataConstructor.apply( new DataType[] { DataTypes.INT(), DataTypes.STRING(), DataTypes.STRING(), DataTypes.INT() }); @Override public void run(SourceContext<RowData> ctx) throws Exception { while (!cancelled) { Thread.sleep(random.nextInt(10) + 5); synchronized (ctx.getCheckpointLock()) { final Object[] rowDataFields = { 2000 + random.nextInt(20), generateRandomWord(4), randomOffences(), caseNo.incrementAndGet() }; ctx.collect(rowDataConstructor.constructInsert(rowDataFields)); pullCount.incrementAndGet(); } } } @Override public void cancel() { cancelled = true; } private String generateRandomWord(int wordLength) { StringBuilder sb = new StringBuilder(wordLength); for (int i = 0; i < wordLength; i++) { // For each letter in the word char tmp = (char) ('a' + random.nextInt('z' - 'a')); // Generate a letter between a and z sb.append(tmp); // Add it to the String } return sb.toString(); } private String randomOffences() { return offences.get(random.nextInt(2)); } }
CeGatewaySinkDataStreamExample.java 数据 sink 样例
package com.bytedance.bytehouse.ce.examples; import com.bytedance.bytehouse.flink.connector.clickhouse.ClickHouseSinkFunction; import com.bytedance.bytehouse.flink.connector.clickhouse.api.java.ClickHouseSinkFunctionBuilder; import java.time.Duration; import java.util.Arrays; import java.util.List; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.DataTypes; import org.apache.flink.table.catalog.Column; import org.apache.flink.table.data.RowData; // CHECKSTYLE:OFF: checkstyle:InvalidTarget /** * Showcasing the usage of ByteHouse CE connector to sink data into a ByteHouse CE table. * * <p>An example of a SQL statement to create a local table compatible with this program is as * follows: * * <pre> * CREATE TABLE `demo_db`.`demo_table_local` ON CLUSTER `demo_cluster` ( * `year` Int32, * `npc` String, * `offence` String, * `case_no` Int32 * ) * ENGINE = HaUniqueMergeTree(('/clickhouse/demo_cluster/demo_table/{shard}', '{replica}')) * ORDER BY `case_no`; * </pre> */ public class CeSinkDataStreamExample { public static void main(String[] args) throws Exception { final String host = args[0]; final int port = Integer.parseInt(args[1]); final String username = args[2]; final String password = args[3]; final String clusterName = args[4]; final String dbName = args[5]; final String tableName = args[6]; // Creating the execution environment final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Adding a source to the data stream DataStream<RowData> dataStream = env.addSource(new DummyRowDataSource()).returns(TypeInformation.of(RowData.class)); // List of columns representing the table schema List<Column> columns = Arrays.asList( Column.physical("year", DataTypes.INT()), Column.physical("npc", DataTypes.STRING()), Column.physical("offence", DataTypes.STRING()), Column.physical("case_no", DataTypes.INT())); try (@SuppressWarnings("unchecked") ClickHouseSinkFunction<RowData, ?> sink = new ClickHouseSinkFunctionBuilder.Upsert(clusterName, dbName, tableName) .withSchema(columns) .withShardDiscoveryKind("CE_GATEWAY") .withGateway(host, port) .withAccount(username, password) .withShardingKey("year") .withFlushInterval(Duration.ofSeconds(1)) .build()) { // Add the sink to the data stream dataStream.addSink(sink); // Trigger the execution env.execute(CeSinkDataStreamExample.class.getSimpleName()); } } }
编译项目生成可运行 jar
为了减少潜在的包冲突文件,建议用户打 fat jar,集成相关依赖。
在项目 pom.xml 文件中,添加如下build方式,以生成 fat jar。
<build> <finalName>fat-jar-example</finalName> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.4.2</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>assemble-all</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
上传 jar 包到 EMR 集群
可通过 scp 指令。
scp xxxx.jar root@xxx.xxx.xxx.xxx:/{path}/
执行任务
提交任务的命令:
/usr/lib/emr/current/flink/bin/flink run-application -t yarn-application <JAR 包文件名>
注意
- 可以以 flink 用户身份运行
- 运行前执行
export HADOOP_CONF_DIR=/etc/emr/hadoop/conf
Yarn ResourceManager UI 查看运行状态

Yarn ResourceManager UI 访问方式,可参考访问链接 E-MapReduce-火山引擎。