E-MapReduce
- 文档首页 /E-MapReduce/组件操作指南/Trino/使用说明
Trino(或 PrestoSQL)是一个高度并行的分布式查询引擎,适用于高效、低延迟的查询分析场景。Trino 本身不存储数据,而是以连接器(Connector)的形式支持访问多种数据源,同时也支持在单个查询中分析来自多个数据源的数据,即联邦查询。
1 组件说明
火山引擎 E-MapReduce(EMR) Trino 采用与 YARN 混合部署模式,即 Coordinator 部署在 master 节点,而 Worker 与 YARN NodeManger 同时部署在同一个节点上,二者分别占用节点的部分资源,占用比例允许用户自定义。
Trino 的整体架构如下图所示:
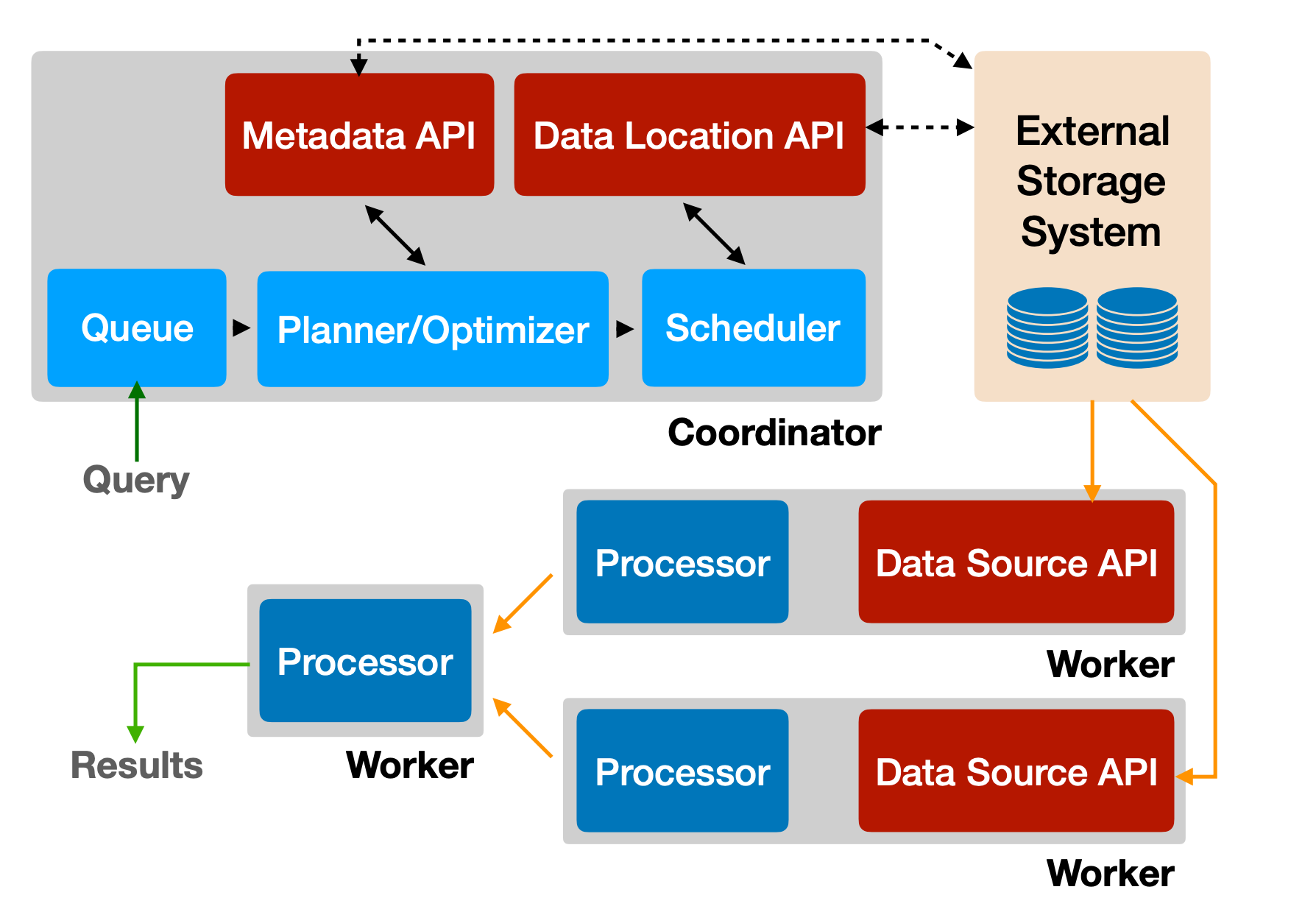
Trino Coordinator:负责接收和解析 SQL 语句,生成并优化查询计划,然后编排并调度 Task 到 Worker 节点上执行。同时,Coordinator 也负责对 Worker 节点的运行状态进行管理。
Trino Worker:负责执行 Coordinator 派发的 Task,基于 Connector 从目标数据源获取并处理数据。Coordinator 最终会从 Worker 节点获取结果并聚合形成最终结果返回给客户端。
Trino Connector:Trino 本身不存储数据,而是通过 Connector 连接访问外部数据源,Connector 可以看做是数据源的驱动程序。
Trino Cli:Trino 提供的命令行工具,支持用户以命令行的形式连接至 Trino Coordinator 节点提交 SQL 查询语句。
2 更多信息
接下来,您可以继续深入访问以下 Trino 相关文档:
基础使用:了解如何基于 Cli 命令行、JDBC、Hue,以及 Airflow 等方式访问 Trino。
高阶使用:了解 EMR Trino 的一些高级特性,例如 Connector 配置、资源组配置、服务化 Web UI,以及高可用支持等。
常见问题:了解您可能会遇到的一些高频问题,以及如何予以解决。
如果您希望了解关于 Trino 更多详细信息,可以参考 Trino 官方文档,或 官方论文。