导航
E-MapReduce
搜索目录或文档标题搜索目录或文档标题
产品动态与公告
产品简介
发行版本
EMR on ECS
发行版本
版本说明
EMR 3.x版本
EMR-3.6.X 版本说明
EMR-3.4.X 版本
EMR 2.x版本
EMR 1.x版本
EMR 1.3.x版本
产品计费
快速入门
EMR on ECS 操作指南
集群管理
集群配置
集群监控
EMR on VKE 操作指南
EMR Serverless 操作指南
EMR Serverless 队列
EMR Serverless 实例(OLAP)
操作指南
数据湖查询(StarRocks)
性能调优
组件操作指南
MapReduce2
Hive
Spark
Spark(仅适用于EMR on VKE形态)
Spark(仅适用于EMR Serverless Spark形态)
Presto(仅适用于Serverless形态)
Knox
OpenLDAP
Ranger
HBase
Phoenix
Tez
Iceberg
StarRocks
数据湖分析
最佳实践
Proton
基础使用
高阶使用
Livy
Celeborn
Celeborn(仅适用于EMR on VKE形态)
Ray(仅适用于EMR on VKE及EMR Serverless形态)
Raycluster使用
最佳实践
EMR on ECS最佳实践
EMR on VKE最佳实践
开发参考
API 参考
EMR on ECS API参考
集群管理
节点组管理
用户管理
用户组管理
应用管理
EMR on VKE API参考
集群管理
应用管理
EMR Serverless API参考
SDK 参考
EMR on ECS SDK 参考
EMR Serverless SDK 参考
- 文档首页 /E-MapReduce/组件操作指南/Tez/使用说明
使用说明
最近更新时间:2024.07.09 16:39:37首次发布时间:2022.05.18 15:11:29
我的收藏
有用
有用
无用
无用
文档反馈
本文为您介绍如何通过火山引擎 E-MapReduce(EMR)集群,使用 Tez 执行 SQL 作业。
1 概述
TEZ 的诞生主要是为了解决 MapReduce 效率低下的问题。
TEZ 将原有的 Map 和 Reduce 两个操作简化为一个概念-Vertex;并将原有的计算处理节点拆分成多个组成部分:Vertex Input、Vertex Output、Sorting、Shuffing和Merging。
计算节点之间的数据通信被称为 Edge,这些分解后的元操作可以任意灵活组合,产生新的操作,这个操作经过组装之后,形成一个大的 DAG 作业。
- Input:对输入数据源的抽象,它解析输入数据格式,并吐出一个个 Key/value。
- Output:对输出数据源的抽象,它将用户程序产生的 Key/value 写入文件系统。
- Paritioner:对数据进行分片,类似于MR中的Partitioner。
- Processor:对计算的抽象,它从一个Input中获取数据,经处理后,通过Output输出。
- Task:对任务的抽象,每个Task由一个Input、Ouput和Processor组成。
- Maser :管理各个Task的依赖关系,并按顺依赖关系执行他们。
除了以上6种组件,Tez 还提供了两种算子,分别是 Sort(排序)和 Shuffle(混洗),为了用户使用方便,它还提供了多种 Input、Output、Task 和 Sort 的实现。
2 前提条件
- 已创建好包含 Hive 组件服务的 EMR 集群。详见创建集群。
- 已安装 OpenLDAP 服务并添加有用户。
3 操作指南
3.1 使用 Hive 提交 Tez 任务
使用 Hive 提交 Tez 任务,需先将 Hive 切换 Tez 为执行引擎:
- 登录 EMR 控制台。
- 在左侧导航栏中,单击进入集群管理 > 集群列表 > 集群详情 > 服务列表 > Hive > 服务参数界面。
- 修改 Hive 参数
hive.execution.engine为 Tez,在右上角单击服务操作 > 重启按钮,重启 Hive 服务。
3.2 登录 EMR master 节点
- 单击集群列表 > 集群名称 > 服务列表 > Hive > 部署拓扑页签,进入 Hive 组件服务的部署拓扑界面。
- 展开 HiveServer2 组件名称,单击 emr-master-1-1 主机名称的 ECS ID,跳转进入到云服务器的实例界面,点击右上角的远程连接按钮。

- 选择一种远程连接方式(推荐选择 ECS Terminal),并输入集群相关认证信息,登录到 Hive 集群的命令行环境中,来执行相关命令行操作。
3.3 连接 hiveserver2
执行以下命令,通过 beeline 连接 HiveServer2:
beeline -u jdbc:hive2://emr-master-1-1:10000 -n <user> -p <password>
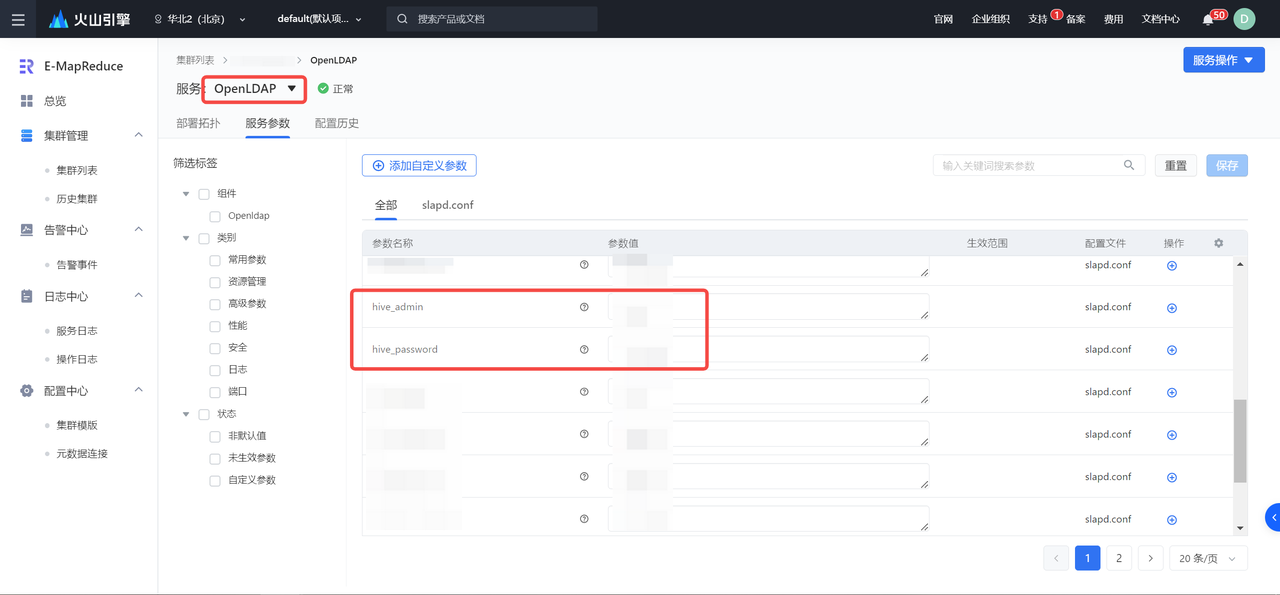
说明
首次进入时,初始化账户密码,您可进入服务列表 > OpenLDAP 组件服务 > 服务参数界面,来获取 Hive 的登录信息。
3.4 执行 hive 语句
连接 HiveServer2 后,您可根据实际场景执行相关 Hive 语句,示例如下:
0: jdbc:hive2://emr-master-1-1:10000> select orderkey,count(*) from lineitem group by orderkey limit 100;