导航
E-MapReduce
搜索目录或文档标题搜索目录或文档标题
产品动态与公告
产品简介
发行版本
EMR on ECS
发行版本
版本说明
EMR 3.x版本
EMR-3.6.X 版本说明
EMR-3.4.X 版本
EMR 2.x版本
EMR 1.x版本
EMR 1.3.x版本
产品计费
快速入门
EMR on ECS 操作指南
集群管理
集群配置
集群监控
EMR on VKE 操作指南
EMR Serverless 操作指南
EMR Serverless 队列
EMR Serverless 实例(OLAP)
操作指南
数据湖查询(StarRocks)
性能调优
组件操作指南
MapReduce2
Hive
Spark
Spark(仅适用于EMR on VKE形态)
Spark(仅适用于EMR Serverless Spark形态)
Presto(仅适用于Serverless形态)
Knox
OpenLDAP
Ranger
HBase
Phoenix
Tez
Iceberg
StarRocks
数据湖分析
最佳实践
Proton
基础使用
高阶使用
Livy
Celeborn
Celeborn(仅适用于EMR on VKE形态)
Ray(仅适用于EMR on VKE及EMR Serverless形态)
Raycluster使用
最佳实践
EMR on ECS最佳实践
EMR on VKE最佳实践
开发参考
API 参考
EMR on ECS API参考
集群管理
节点组管理
用户管理
用户组管理
应用管理
EMR on VKE API参考
集群管理
应用管理
EMR Serverless API参考
SDK 参考
EMR on ECS SDK 参考
EMR Serverless SDK 参考
- 文档首页 /E-MapReduce/EMR Serverless 操作指南/EMR Serverless 实例(OLAP)/操作指南/表存储格式/表存储格式介绍
表存储格式介绍
最近更新时间:2024.02.18 19:02:02首次发布时间:2024.01.12 14:29:13
我的收藏
有用
有用
无用
无用
文档反馈
EMR StarRocks支持列存和行存的存储格式、和行列混存。本文介绍行存和列存的概念, 实现的原理以及各自适用的应用场景。
1 列式存储
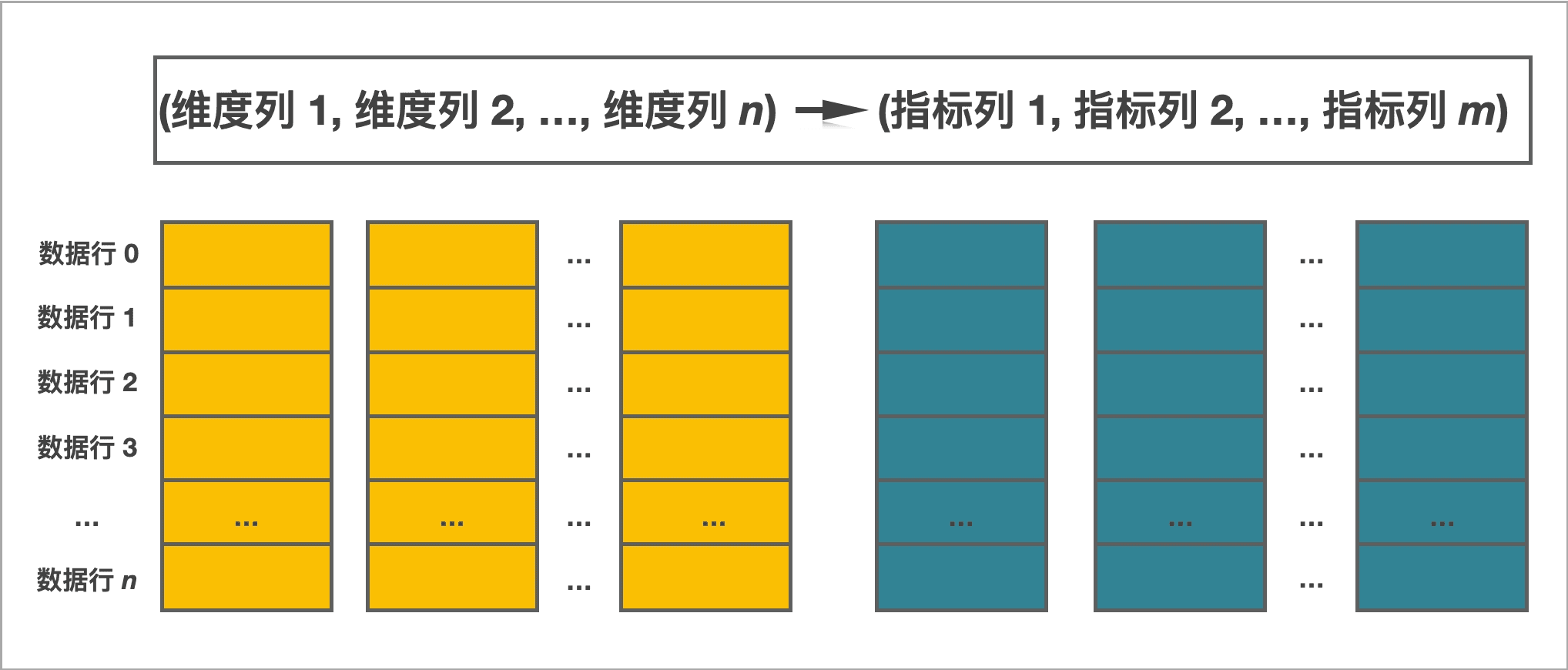
表数据按列存储。物理上,一列数据会经过分块编码、压缩等操作,然后持久化存储到非易失设备上。但在逻辑上,一列数据可以看成是由相同类型的元素构成的一个数组。 一行数据的所有列值在各自的数组中按照列顺序排列,即拥有相同的数组下标。数组下标是隐式的,不需要存储。表中所有的行按照维度列,做多重排序,排序后的位置就是该行的行号。
查询时,如果指定了维度列上的等值条件或者范围条件、并且这些条件中的维度列可以构成表的维度列前缀,则可以利用数据的有序性,使用二分查找法快速锁定目标行。原理可以参考官网理解StarRocks表设计。
2 行式存储
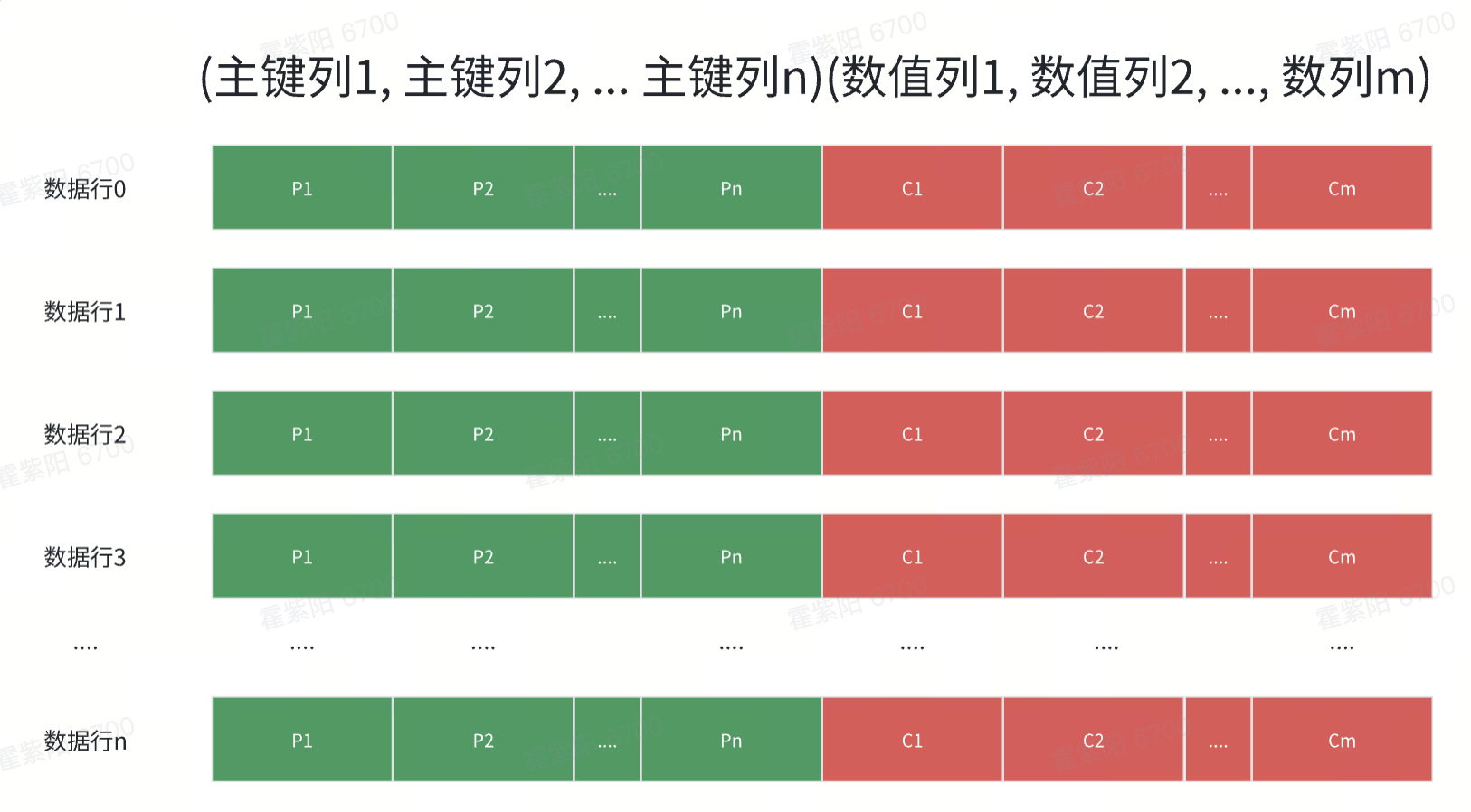
行存格式与列存正好相反, 数据按照每一行将所有列都紧凑的排列在一起, 每一行的数据经过编码后按照字节序存储到磁盘上.
行存表在查询时候非常直观, 数据一条一条的从存储引擎中获取到, 然后根据一系列的过滤选择聚合排序等计算返回相应的结果.
3 适用场景
| 存储格式 | 适用场景 | 使用限制 | 使用说明 |
|---|---|---|---|
列存 | 适用于OLAP场景,适合各种复杂查询、数据关联、扫描、过滤和统计。 |
| 与开源的StarRocks保持一致 |
行存 | 适合基于Primary Key点查点更新的场景,提供在线服务。 |
| 行存采用主键模型,采用主键查询、插入、更新时,性能较好。 |
3.1使用建议
是否使用行存表, 可以从下面几个维度考虑:
查询场景
- 基于主键等值条件的查询,而且需要非常高的QPS。
更新场景
- 基于主键时更新,而且需要非常高频的更新。
插入场景
整行插入或者部分列插入, 而且需要非常高频的插入
数据链路时延要求低
3.2 使用限制
有大量非主键类扫描表的查询, 尽量谨慎使用行存表。
有复杂多表关联, 且表没有主键过滤的场景查询,不建议使用行存表。