导航
代码示例
最近更新时间:2022.09.30 11:40:11首次发布时间:2022.07.28 17:33:38
本文通过示例向您介绍 Spark Operator、Hive Operator 与 Presto(Trino) Operator 的使用方式,熟悉 Airflow 与其他大数据组件的协同工作方式。
1 前提条件
以下示例都基于添加了 Airflow 与 Presto 服务的 Hadoop 类型集群,集群创建操作详见:创建集群。
2 Spark Operator 使用示例
场景说明:通过 spark-submit 运行了 SparkPi 样例,之后通过 spark-sql 提交了新建表的请求,插入数据并查看,最后运行了 UDF 函数。
该场景覆盖了 Spark 在日常工作中涉及到的主要 case,Airflow 为 Spark 提供了两个 Operator 支持,SparkSubmitOperator 与 SparkSQLOperator。
from airflow.models import DAG from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator from airflow.providers.apache.spark.operators.spark_sql import SparkSqlOperator from airflow.utils.dates import days_ago args = { 'owner': 'hive', } with DAG( dag_id='emr_spark_test', default_args=args, schedule_interval='30 * * * *', start_date=days_ago(2), tags=['example'], ) as dag: spark_submit_case = SparkSubmitOperator( task_id='spark_submit', dag=dag, application= 'path_to_example_jar', java_class='org.apache.spark.examples.SparkPi', name='airflow-spark-submit' # executor_cores= 1, # executor_memory='1g', # driver_memory='1g', ) # [START emr-demo] create_table_job = SparkSqlOperator( task_id='run_first', sql=''' create database if not exists airflow; use airflow; drop table if exists sparksql_operator_test; create table sparksql_operator_test(name string); insert into sparksql_operator_test values('test'); ''', name='airflow-spark-sql-create-table' # conn_id='spark_sql_default', # keytab=Node, # total_executor_cores=None, # executor_cores=None, # executor_memory=None, # conf='spark.sql.shuffle.partitions=100', # principal=None, # master='yarn', # num_executors=None, # verbose=True, # yarn_queue='default' ) select_job = SparkSqlOperator( task_id='run_second', sql=''' use airflow; select name from sparksql_operator_test; ''', master='yarn', name='airflow-spark-sql-select' ) udf_case = SparkSqlOperator( task_id='run_second', sql=''' use airflow; select udf_name(name) from sparksql_operator_test; ''', master='yarn', name='airflow-spark-sql-select' ) spark_submit_case >> create_table_job >> select_job >> udf_case # [END how_to_operator_spark_sql]
3 Hive Operator 使用示例
场景说明:通过 HiveSQL 创建了表并插入数据,最后运行 UDF。
Airflow 提供的 HiveOperator 用以执行 HiveSQL,可以覆盖以上场景。
from airflow import DAG from airflow.operators.hive_operator import HiveOperator from datetime import datetime, timedelta from airflow.models import Variable default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': datetime(2019, 6, 1), 'email': ['airflow@example.com'], 'email_on_failure': False, 'email_on_retry': False, 'retries': 1, 'retry_delay': timedelta(minutes=1), 'end_date': datetime(9999, 1, 1),} dag = DAG( 'hive_test_dag', default_args=default_args, schedule_interval='30 10 * * *', catchup=False) hive_create_case = HiveOperator( task_id='hive_test_task', hive_cli_conn_id='hiveserver2_emr', schema='default', hql=''' CREATE TABLE IF NOT EXISTS employee ( eid int, name String, salary String, destination String) COMMENT 'Employee details' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE; ''', dag=dag) hive_select_case = HiveOperator( task_id='hive_test_task', hive_cli_conn_id='hiveserver2_emr', schema='default', hql='select * from employee', dag=dag) hive_udf_case = HiveOperator( task_id='hive_test_task', hive_cli_conn_id='hiveserver2_emr', schema='default', hql='select udf_name(name) from employee', dag=dag) hive_create_case >> hive_select_case >> hive_udf_case
4 Presto Operator 使用示例
场景说明:通过 Presto 新建了表,插入数据并将其读取出来。
Airflow 提供的 Presto Provider 中功能比较有限,提供了最基本的 presto_hook,我们需要自己基于该 hook 编写 Python 方法来完成工作,不能简单通过 Operator 对象的新建与编排来完成工作流。Airflow 提供了一个通用的 PythonOperator,用来让我们得以调度任意 Python 方法。
from airflow import DAG from airflow.hooks.presto_hook import PrestoHook from airflow.operators.python_operator import PythonOperator from datetime import timedelta default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date':airflow.utils.dates.days_ago(0), 'email': ['airflow@example.com'], 'email_on_failure': True, 'email_on_retry': False, 'retries':3, 'retry_delay':timedelta(minutes=15),} dag = DAG( 'Presto-demo', default_args=default_args, description='Presto demo', schedule_interval=timedelta(minutes=30)) # 使用presto的connector_id,这个Conn已经为您初始化创建了 ph = PrestoHook( presto_conn_id='presto', catalog='hive', schema='default', port=8080) def presto_drop_table(**context): sql = """DROP TABLE IF EXISTS tb_airflow_demo""" data = ph.get_records(sql) return True def presto_create_table(**context): sql = ''' CREATE TABLE IF NOT EXISTS tb_airflow_demo(id int, name varchar) ''' data = ph.get_records(sql) return True def presto_insert_data(**context): sql = ''' INSERT INTO tb_airflow_demo SELECT 1, 'name1' ''' data = ph.get_records(sql) return True def presto_select_data(**context): sql = ''' SELECT * FROM tb_airflow_demo LIMIT 20 ''' data = ph.get_records(sql) return True # drop table最好不要执行,presto不配置,一般没有这个权限,任务会执行失败 #presto_drop_table_task = PythonOperator(task_id='presto_drop_table',provide_context=True,python_callable=presto_drop_table,dag=dag) presto_create_table_task = PythonOperator( task_id='presto_create_table', provide_context=True, python_callable=presto_create_table, dag=dag) presto_insert_data_task = PythonOperator( task_id='presto_insert_data', provide_context=True, python_callable=presto_insert_data, dag=dag) presto_select_data_task = PythonOperator( task_id='presto_select_data', provide_context=True, python_callable=presto_select_data, dag=dag) presto_create_table_task >> presto_insert_data_task >> presto_select_data_task if __name__ == "__main__": dag.cli()
4.1 Presto 中的 DROP/ALTER 权限
该 DAG 示例注释掉了drop_table的部分,若您希望能在 Presto 执行时有 drop/alter table 权限,请按图示前往 EMR 控制台为 Presto 组件新增配置项,配置项如下。
hive.allow-drop-table=true hive.allow-rename-table=true hive.allow-add-column=true hive.allow-drop-column=true hive.allow-rename-column=true
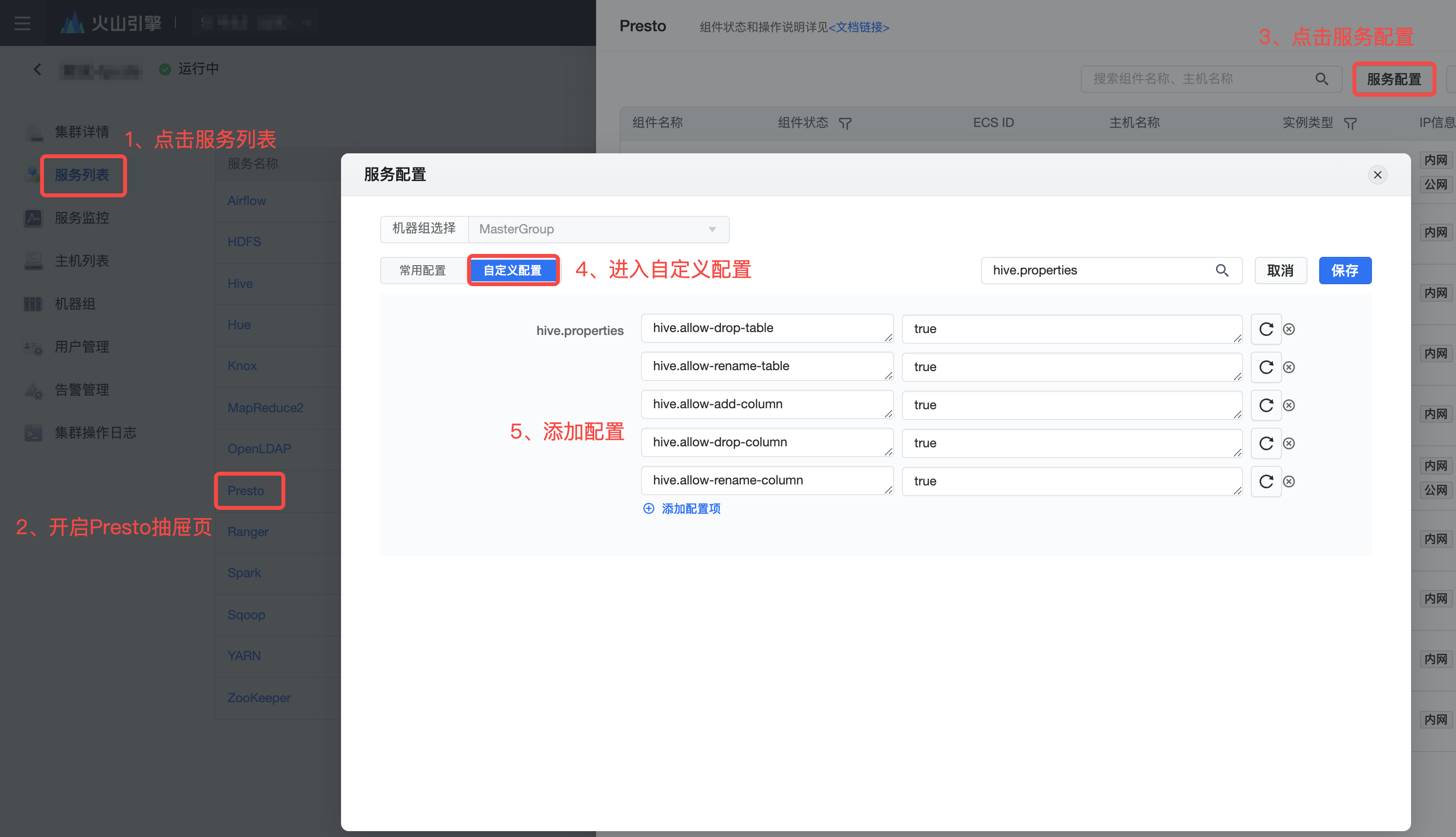
- 添加配置完毕部署后,请您重启组件。