Routine Load 是一种基于 MySQL 协议的异步导入方式,支持持续消费 Apache Kafka的消息并导入至 StarRocks 中。本文介绍 Routine Load 的基本原理、以及如何通过 Routine Load 导入至 StarRocks 中。本文图片和内容来源于开源StarRocks的从Apache Kafka持续导入。
1 基本原理
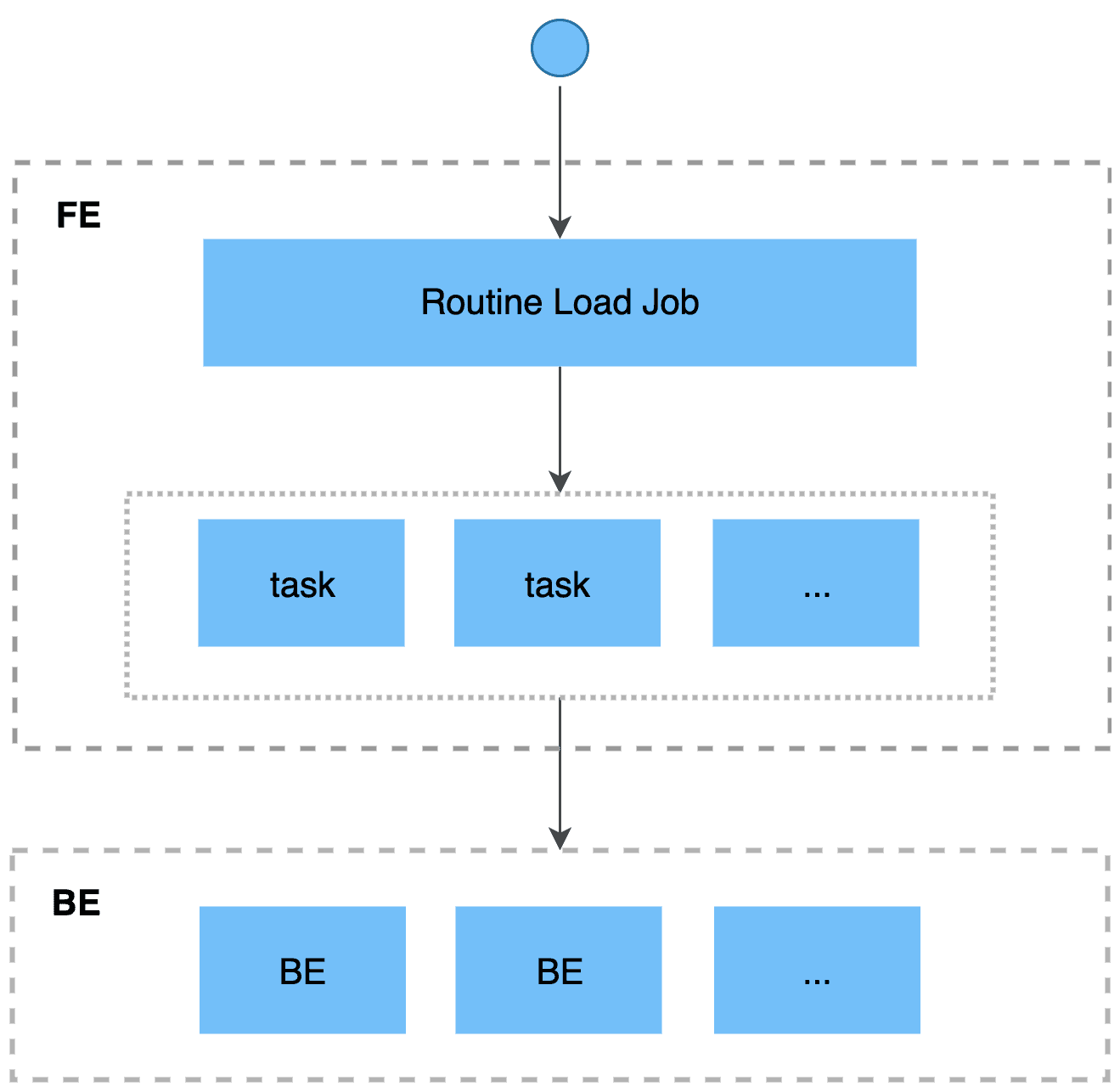
导入流程如下:
客户端向FE提交创建导入作业的 SQL 语句,FE解析SQL语句后,创建常驻的导入作业。
FE按照一定规则将导入作业拆分成若干导入任务。一个导入任务作为一个独立的事务。
每个导入任务被分配到指定的BE上执行。
BE导入任务执行完成后,向FE汇报。
FE根据汇报结果,继续生成新的导入任务,或者对失败的导入任务进行重试,连续地导入数据,并且能够保证导入数据不丢不重。
2 导入流程
Routine Load 支持通过无安全认证、SSL 加密和认证、或者 SASL 认证机制访问 Kafka。
Routine Load 支持从 Kakfa 集群中消费 CSV、JSON 格式的数据。对于CSV格式的是数据:支持长度不超过50个字节的UTF-8 编码字符串作为列分隔符;空值用 \N 表示。
2.1 创建导入任务
通过CREATE ROUTINE LOAD命令创建Routine Load导入作业。
语法:
CREATE ROUTINE LOAD [<database_name>.]<job_name> ON <table_name> [load_properties] [job_properties] FROM data_source [data_source_properties]
参数说明:
| 参数 | 描述 |
|---|---|
| database_name | 选填,目标数据库的名称。 |
| job_name | 必填,导入作业的名称。 |
| table_name | 必填,目标表的名称。 |
| load_properties | 选填。源数据的属性。支持的属性参考StarRocks社区 load_properties。 |
job_properties | 必填。导入作业的属性。语法: |
| data_source | 必填。指定数据源,目前仅支持取值为 KAFKA。 |
| data_source_properties | 必填。数据源属性。参考StarRocks社区data_source_properties`介绍。 | |
2.2 查看任务状态
通过SHOW ROUTINE LOAD命令查看 routine load 任务的信息。
- 展示所有例行导入作业(包括已停止或取消的作业),结果为一行或多行。
-- 查看某个数据库下所有ROUTINE LOAD导入作业 USE <db_name>; SHOW ALL ROUTINE LOAD \G; -- 查看某个数据库下某个ROUTINE LOAD导入作业 SHOW ROUTINE LOAD FOR <db_name>.<job_name>;
执行SHOW ROUTINE LOAD命令,可以查看当前正在运行的所有Routine Load任务,返回如下类似信息。
*************************** 1. row *************************** Id: 10160 Name: example_tbl1_ordertest1 CreateTime: 2023-09-23 10:43:47 PauseTime: NULL EndTime: NULL DbName: example_db TableName: example_tbl1 State: RUNNING DataSourceType: KAFKA CurrentTaskNum: 3 JobProperties: {"partitions":"*","rowDelimiter":"\t","partial_update":"false","columnToColumnExpr":"order_id,pay_dt,customer_name,nationality,temp_gender,price","maxBatchIntervalS":"10","whereExpr":"*","timezone":"Asia/Shanghai","format":"csv","columnSeparator":"','","json_root":"","maxFilterRatio":"1.0","strict_mode":"false","jsonpaths":"","desireTaskConcurrentNum":"5","maxErrorNum":"0","strip_outer_array":"false","currentTaskConcurrentNum":"3","maxBatchRows":"200000"} DataSourceProperties: {"topic":"ordertest1","currentKafkaPartitions":"0,1,2,3,4","brokerList":"192.168.10.17:9092"} CustomProperties: {"kafka_default_offsets":"OFFSET_BEGINNING","group.id":"example_tbl1_ordertest1_f205c7f5-bda9-4755-9e63-361eb8d774c2"} Statistic: {"receivedBytes":314,"errorRows":0,"committedTaskNum":2,"loadedRows":6,"loadRowsRate":0,"abortedTaskNum":2,"totalRows":6,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":2068} Progress: {"0":"OFFSET_ZERO","1":"OFFSET_ZERO","2":"0","3":"0","4":"7"} ReasonOfStateChanged: ErrorLogUrls: OtherMsg:
相关参数描述如下:
State:导入任务状态。RUNNING表示该导入任务处于持续运行中。
Statistic:进度信息,记录了从创建任务开始后的导入信息。包含:接收到的数据大小、导入错误行数、已导入的行数、导入数据速率、接收的总行数等信息。
Progress:各个分区的消费进度。
2.3 暂停导入任务
执行 PAUSE ROUTINE LOAD 语句后,会暂停导入作业。导入作业会进入 PAUSED 状态,但是导入作业未结束,您可以执行 RESUME ROUTINE LOAD 语句重启该导入作业。您也可以执行 SHOW ROUTINE LOAD 语句查看已暂停的导入作业的状态。
-- 暂停导入作业 PAUSE ROUTINE LOAD FOR <db_name>.<job_name>;
暂停导入任务后,任务的State变更为PAUSED,Statistic和Progress中的导入信息停止更新。
2.4 恢复导入任务
执行 RESUME ROUTINE LOAD,恢复导入作业。导入作业会先短暂地进入 NEED_SCHEDULE 状态,表示正在重新调度导入作业,一段时间后会恢复至 RUNNING 状态,继续消费 Kafka 消息并且导入数据。您可以执行 SHOW ROUTINE LOAD 语句查看已恢复的导入作业。
-- 恢复导入作业 RESUME ROUTINE LOAD FOR <db_name>.<job_name>;
2.5 修改导入任务
修改前,您需要先执行 PAUSE ROUTINE LOAD 暂停导入作业。然后执行 ALTER ROUTINE LOAD 语句,修改导入作业的参数配置。修改成功后,您需要执行 RESUME ROUTINE LOAD,恢复导入作业。然后执行 SHOW ROUTINE LOAD 语句查看修改后的导入作业。
-- 修改导入作业,参数介绍参考[ALTER ROUTINE LOAD](https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/data-manipulation/alter-routine-load) 语句 ALTER ROUTINE LOAD FOR [db_name.]job_name [load_properties] [job_properties] FROM data_source [data_source_properties]
2.6 停止导入任务
执行 STOP ROUTINE LOAD,可以停止导入作业。导入作业会进入 STOPPED 状态,代表此导入作业已经结束,且无法恢复。再次执行 SHOW ROUTINE LOAD 语句,将无法看到已经停止的导入作业。
STOP ROUTINE LOAD FOR <job_name>;
3 最佳实践案例
3.1 导入CSV格式数据
在Kafka集群中执行以下操作,准备源数据
创建Topic
/usr/lib/emr/current/kafka/bin/kafka-topics.sh --create --bootstrap-server `hostname -i`:9092 --topic ordertest1 --replication-factor 3 --partitions 10执行Kafka生成数据命令
/usr/lib/emr/current/kafka/bin/kafka-console-producer.sh --broker-list `hostname -i`:9092 --topic ordertest1在Kafka生成数据命令的控制台,输入以下测试数据
2020050802,2020-05-08,Johann Georg Faust,Deutschland,male,895 2020050802,2020-05-08,Julien Sorel,France,male,893 2020050803,2020-05-08,Dorian Grey,UK,male,1262 2020050901,2020-05-09,Anna Karenina,Russia,female,175 2020051001,2020-05-10,Tess Durbeyfield,US,female,986 2020051101,2020-05-11,Edogawa Conan,japan,male,8924
在StarRocks集群中执行导入kafka数据的动作。
创建目标数据库和数据表
根据 CSV 数据中需要导入的几列(例如除第五列性别外的其余五列需要导入至 StarRocks), 在 StarRocks 集群创建目标数据库和目标表。
CREATE DATABASE IF NOT EXISTS example_db; CREATE TABLE example_db.example_tbl1 ( `order_id` bigint NOT NULL COMMENT "订单编号", `pay_dt` date NOT NULL COMMENT "支付日期", `customer_name` varchar(26) NULL COMMENT "顾客姓名", `nationality` varchar(26) NULL COMMENT "国籍", `price`double NULL COMMENT "支付金额" ) ENGINE=OLAP DUPLICATE KEY (order_id,pay_dt) DISTRIBUTED BY HASH(`order_id`) BUCKETS 5;执行导入作业
提交 Routine Load 导入作业,从Kafka Topic 所指定分区的最早位点 (Offset) 开始消费持续消费数据。
CREATE ROUTINE LOAD example_db.example_tbl1_ordertest1 ON example_tbl1 COLUMNS TERMINATED BY ",", COLUMNS (order_id, pay_dt, customer_name, nationality, temp_gender, price) PROPERTIES ( "desired_concurrent_number" = "5" ) FROM KAFKA ( "kafka_broker_list" ="192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092", "kafka_topic" = "ordertest1", "kafka_partitions" ="0,1,2,3,4", "property.kafka_default_offsets" = "OFFSET_BEGINNING" );
说明
1. temp_gender字段属于占位,使得CSV中数据中列和目标表中的列名对应。 2. desired_concurrent_number参数:导入并发度,指定一个导入任务最多会被分成多少个子任务执行。非必填参数,默认值为3。Job支持参数可参考StarRocks社区[job_properties](https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/data-manipulation/CREATE_ROUTINE_LOAD#job_properties)。 3. kafka_partitions参数:待消费的分区。非必填参数,默认消费所有分区。 4. kafka_offsets参数:待消费分区的起始消费位点。
c. 查看导入任务的信息
SHOW ROUTINE LOAD FOR example_db.example_tbl1_ordertest1;
d. 查询目标表中的数据,确认数据已完成同步
SELECT count(*) from example_db.example_tbl1;
e. 对导入任务还可以执行以下操作:
- 暂停导入任务
PAUSE ROUTINE LOAD FOR example_db.example_tbl1_ordertest1;
- 修改导入任务
ALTER ROUTINE LOAD FOR example_db.example_tbl1_ordertest1 PROPERTIES ( "desired_concurrent_number" = "1" );
说明
仅支持修改状态为PAUSED的任务。
- 恢复导入任务
RESUME ROUTINE LOAD FOR example_db.example_tbl1_ordertest1;
- 停止导入任务
STOP ROUTINE LOAD FOR example_db.example_tbl1_ordertest1;
3.2 导入JSON格式数据
在Kafka集群中执行以下操作,准备源数据
创建Topic
/usr/lib/emr/current/kafka/bin/kafka-topics.sh --create --bootstrap-server `hostname -i`:9092 --topic ordertest2 --replication-factor 3 --partitions 10执行Kafka生成数据命令
/usr/lib/emr/current/kafka/bin/kafka-console-producer.sh --broker-list `hostname -i`:9092 --topic ordertest2在Kafka生成数据命令的控制台,输入以下JSON格式的测试数据
要求每行一个 JSON 对象必须在一个 Kafka 消息中,否则会出现“JSON 解析错误”的问题
{"commodity_id": "1", "customer_name": "Mark Twain", "country": "US","pay_time": 1589191487,"price": 875} {"commodity_id": "2", "customer_name": "Oscar Wilde", "country": "UK","pay_time": 1589191487,"price": 895} {"commodity_id": "3", "customer_name": "Antoine de Saint-Exupéry","country": "France","pay_time": 1589191487,"price": 895}
在StarRocks集群中执行导入kafka数据的动作。
- 创建目标数据库和数据表
根据 CSV 数据中需要导入的几列(例如除第五列性别外的其余五列需要导入至 StarRocks), 在 StarRocks 集群创建目标数据库和目标表。
USE example_db; CREATE TABLE `example_tbl2` ( `commodity_id` varchar(26) NULL COMMENT "品类ID", `customer_name` varchar(26) NULL COMMENT "顾客姓名", `country` varchar(26) NULL COMMENT "顾客国籍", `pay_time` bigint(20) NULL COMMENT "支付时间", `pay_dt` date NULL COMMENT "支付日期", `price`double SUM NULL COMMENT "支付金额" ) ENGINE=OLAP AGGREGATE KEY(`commodity_id`,`customer_name`,`country`,`pay_time`,`pay_dt`) DISTRIBUTED BY HASH(`commodity_id`) BUCKETS 5;- 执行导入作业
提交 Routine Load 导入作业,从Kafka Topic 所指定分区的最早位点 (Offset) 开始消费持续消费数据
- 创建目标数据库和数据表
CREATE ROUTINE LOAD example_db.example_tbl2_ordertest2 ON example_tbl2 COLUMNS(commodity_id, customer_name, country, pay_time, price, pay_dt=from_unixtime(pay_time, '%Y%m%d')) PROPERTIES ( "desired_concurrent_number"="5", "format" ="json", "jsonpaths" ="[\"$.commodity_id\",\"$.customer_name\",\"$.country\",\"$.pay_time\",\"$.price\"]" ) FROM KAFKA ( "kafka_broker_list" ="192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092", "kafka_topic" = "ordertest2", "kafka_partitions" ="0,1,2,3,4", "property.kafka_default_offsets" = "OFFSET_BEGINNING" );
说明
- pay_dt字段:是对源数据中
pay_time键转换为 DATE 类型数据后导入该字段。更多数据转换的说明,请参见导入时实现数据转换。 - jsonpaths参数:指定待导入 JSON 数据的 Key。
- 如果 JSON 数据最外层是数组结构,则需要在
PROPERTIES设置"strip_outer_array"="true",表示裁剪最外层的数组结构。并且需要注意在设置jsonpaths时,整个 JSON 数据的根节点是裁剪最外层的数组结构后展平的 JSON 对象。 - 如果不需要导入整个 JSON 数据,则需要使用
json_root指定实际所需导入的 JSON 数据根节点。
c. 查看导入任务的信息
USE example_db; SHOW ROUTINE LOAD FOR example_tbl2_ordertest2 \G;
d. 查询目标表中的数据,确认数据已完成同步
SELECT count(*) from example_db.example_tbl2;